# Building a Large Language Model Inference Network from Scratch
[](https://gitee.com/mindspore/docs/blob/master/tutorials/source_en/model_infer/ms_infer/model_dev.md)
## Large Language Model Backbone Network
Currently, the backbone networks of mainstream large language models are mainly based on the transformer structure. The most important part is the computation of the self-attention mechanism. The following figure uses the Llama2 large language model as an example to describe the backbone network structure.

The core layer of Llama2 consists of the following parts:
- **Embedding**: converts the index corresponding to each token into a vector to implement feature dispersion. Similar to onehot vectorization, the embedding weight is involved in the training process to better adapt to the context semantics in the language model. The process is implemented by an Embedding operator.
- **DecodeLayer**: transformer structure, which is the key for the computation of the large language model. Generally, multi-layer computation is performed based on different configurations. Each layer is actually a transformer structure, which is one of the cores of the foundation language model.
- **RmsNorm&Linear**: outputs linear normalization layer. After computation of the transformer structure, the result is normalized to the same dimension as the model vocabulary, and the probability distribution of each token is returned.
To build a network with MindSpore large language model inference, you can assemble the operators provided by MindSpore. The following is an example to describe how to build a typical transformer model.
## TransformerModel
In a typical transformer model, each layer consists of the normalization, attention, residual connection, and multi-layer perception (MLP). Both attention and MLP meet the requirements of two continuous matrix multiplications.
1. Attention
Currently, the mainstream attention uses the Muli-Head Attention (MHA) structure. The following figure shows the MHA structure. You can construct the attention network based on this structure.
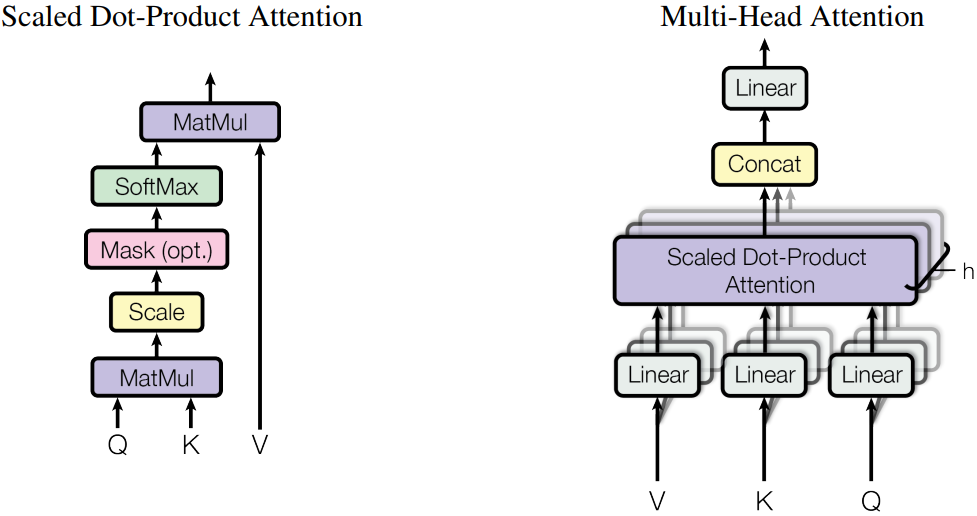
The following is an example of the attention code:
```python
class Attention(nn.Cell):
def __init__(self, config):
super().__init__()
self.num_heads_per_partition = config.num_heads
self.head_dim = config.hidden_size // config.num_heads
self.norm_factor = math.sqrt(self.head_dim)
self.q = nn.Linear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
has_bias=config.has_bias)
self.k = nn.Linear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
self.v = nn.Linear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
self.flash_attention = ops.operations.nn_ops.FlashAttentionScore(head_num=self.num_heads_per_partition,
scale_value=1.0/self.norm_factor,
next_tokens=0)
self.out = nn.Linear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
def construct(self, x, mask):
query = self.q(x)
key = self.k(x)
value = self.v(x)
_, _, _, context_layer = self.flash_attention(query, key, value, attn_mask=mask)
output = self.out(context_layer)
return output
```
You can use the following code to perform the attention computation:
```python
mask = np.ones(shape=(config.seq_length, config.seq_length), dtype=np.uint8)
mask = np.triu(mask, 1)
mask = Tensor(mask)
attention = Attention(config=config)
attention_output = attention(embedding_output, mask)
print(attention_output.shape)
```
2. MLP
MLP consists of two consecutive fully connected layers. The following code is an example:
```python
class MLP(nn.Cell):
def __init__(self, config):
super().__init__()
self.w1 = nn.Linear(in_channels=config.hidden_size,
out_channels=config.ffn_hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
self.w2 = nn.Linear(in_channels=config.ffn_hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
self.act_func = nn.SiLU()
self.mul = ops.Mul()
def construct(self, x):
x = self.w1(x)
x = self.act_func(x)
output = self.w2(x)
return output
```
You can use the following code to perform the attention computation:
```python
mlp = ParallelMLP(config=config)
mlp_output = mlp(attention_output)
print(mlp_output.shape)
```
3. TransformerLayer
The attention and MLP modules can be used to construct the TransformerLayer, that is, DecodeLayer. The details are as follows:
```python
class TransformerLayer(nn.Cell):
def __init__(self, config):
super().__init__()
self.attention = Attention(config=config)
self.feed_forward = MLP(config=config)
self.attention_norm = RMSNorm(dim=config.hidden_size, dtype=config.dtype)
self.ffn_norm = RMSNorm(dim=config.hidden_size, dtype=config.dtype)
self.add = ops.Add()
def construct(self, x, mask):
norm_output = self.attention_norm(x)
attention_output = self.attention(norm_output, mask)
norm_input = self.add(x, attention_output)
norm_output = self.ffn_norm(norm_input)
mlp_output = self.feed_forward(norm_output)
output = self.add(norm_input, mlp_output)
return output
```
You can use the following code to perform the TransformerLayer computation:
```python
transformerlayer = TransformerLayer(config=config)
transformerlayer_output = transformerlayer(embedding_output, mask)
print(transformerlayer_output.shape)
```
4. TransformerModel
Construct a TransformerModel by stacking TransformLayer.
```python
class TransformerModel(nn.Cell):
def __init__(self, config):
super().__init__()
self.embedding = VocabEmbedding(num_embeddings=config.vocab_size,
embedding_dim=config.hidden_size,
init_method='normal',
init_type=config.dtype)
self.layers = nn.CellList()
self.num_layers = config.num_layers
for _ in range(config.num_layers):
layer = TransformerLayer(config=config)
self.layers.append(layer)
self.norm_out = RMSNorm(dim=config.hidden_size, dtype=config.dtype)
def construct(self, x, mask):
hidden_state = self.embedding(x)
for i in range(self.num_layers):
hidden_state = self.layers[i](hidden_state, mask)
hidden_state = self.norm_out(hidden_state)
return hidden_state
```
You can use the following code to perform the TransformerModel computation:
```python
transformer = TransformerModel(config=config)
transformer_output = transformer(input_ids, mask)
print(transformer_output.shape)
```
For details about the end-to-end large language model code project, see [model_dev.py](https://gitee.com/mindspore/docs/blob/master/docs/sample_code/infer_code/model_dev.py) script. Set the size of **CommunicationHelper** to **1**, and run the following command for verification:
```shell
msrun --worker_num 1 --local_worker_num 1 --master_port 8124 --log_dir msrun_log --join True --cluster_time_out 300 model_dev.py
```