性能调试(Ascend-PyNative)
概述
本教程介绍如何在Ascend AI处理器上使用MindSpore Profiler在PyNative模式下进行性能调试。PyNative模式目前支持算子性能分析、算子时间线、数据准备三部分功能。
操作流程
准备训练脚本,并在训练脚本中调用性能调试接口,接着运行训练脚本。
启动MindInsight,并通过启动参数指定summary-base-dir目录(summary-base-dir是Profiler所创建目录的父目录),例如训练时Profiler创建的文件夹绝对路径为
/home/user/code/data,则summary-base-dir设为/home/user/code。启动成功后,根据IP和端口访问可视化界面,默认访问地址为http://127.0.0.1:8080。在训练列表找到对应训练,点击性能分析,即可在页面中查看训练性能数据。
准备训练脚本
为了收集神经网络的性能数据,需要在训练脚本中添加MindSpore Profiler相关接口。
在训练开始前,需要初始化MindSpore
Profiler对象。在训练结束后,调用
Profiler.analyse()停止性能数据收集并生成性能分析结果。
正常场景样例代码如下:
import numpy as np
import mindspore as ms
from mindspore import nn
import mindspore.dataset as ds
class Net(nn.Cell):
def __init__(self):
super(Net, self).__init__()
self.fc = nn.Dense(2, 2)
def construct(self, x):
return self.fc(x)
def generator():
for i in range(2):
yield (np.ones([2, 2]).astype(np.float32), np.ones([2]).astype(np.int32))
def train(net):
optimizer = nn.Momentum(net.trainable_params(), 1, 0.9)
loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True)
data = ds.GeneratorDataset(generator, ["data", "label"])
model = ms.Model(net, loss, optimizer)
model.train(1, data)
if __name__ == '__main__':
ms.set_context(mode=ms.PYNATIVE_MODE, device_target="Ascend")
# Init Profiler
# Note that the Profiler should be initialized before model.train
profiler = ms.Profiler(output_path = './profiler_data')
# Train Model
net = Net()
train(net)
# Profiler end
profiler.analyse()
启动MindInsight
启动命令请参考`MindInsight相关命令 <https://www.mindspore.cn/mindinsight/docs/zh-CN/r1.10/mindinsight_commands.html>`_ 。
训练性能
用户从训练列表中选择指定的训练,点击性能调试,可以查看该次训练的性能数据。
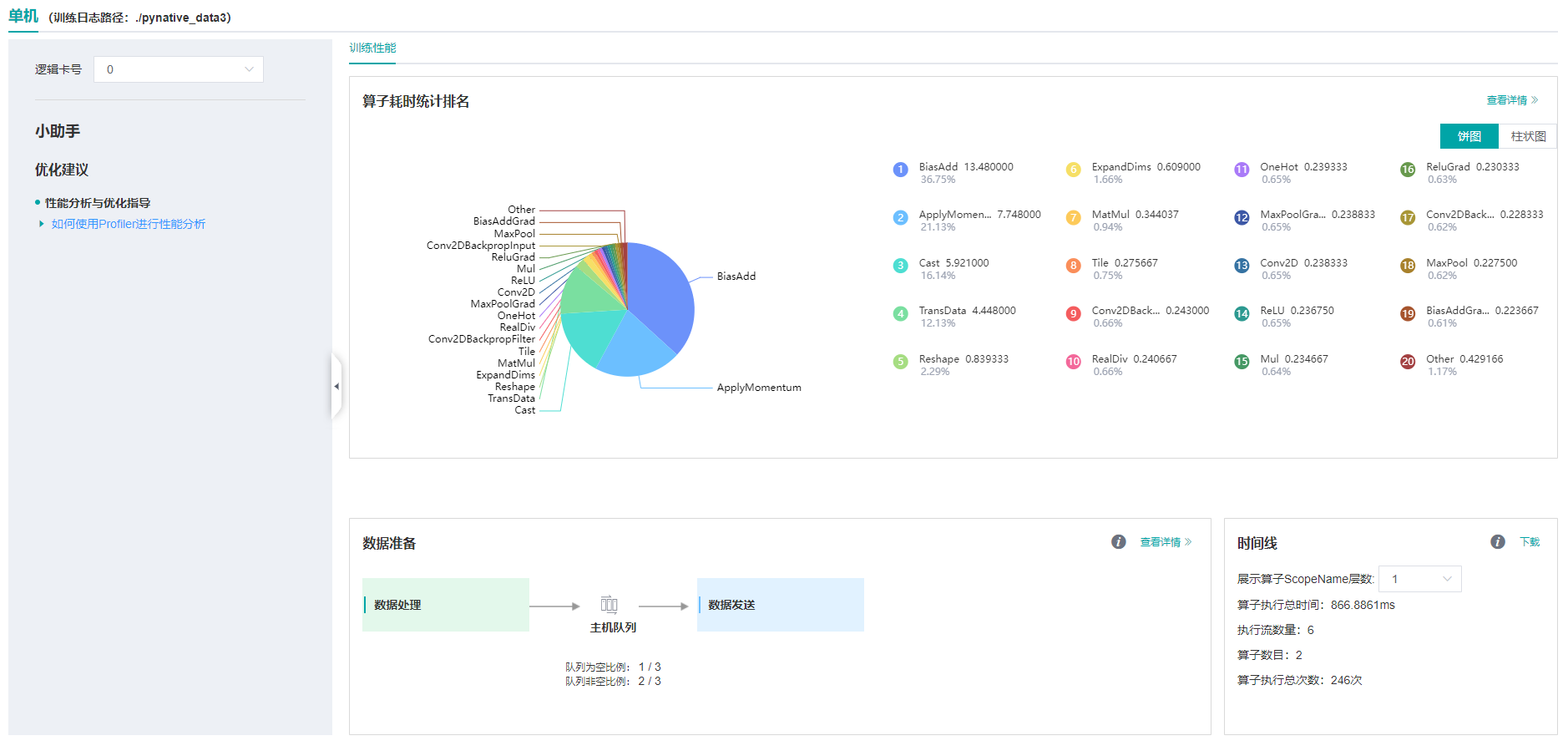
图:性能数据总览
上图展示了性能数据总览页面,包含了算子性能、数据准备性能和Timeline等组件的数据总体呈现。各组件展示的数据如下:
算子性能:统计单算子以及各算子类型的执行时间,进行排序展示;总览页中展示了各算子类型时间占比的饼状图。
数据准备性能:统计训练数据准备各阶段的性能情况;总览页中展示了各阶段性能可能存在瓶颈的step数目。
Timeline:按设备通过时间轴的方式展示每个算子的时序耗时情况;总览页展示了Timeline中的算子统计信息。
用户可以点击查看详情链接,进入某个组件页面进行详细分析。MindInsight也会对性能数据进行分析,在左侧的智能小助手中给出性能调试的建议。
算子性能分析
使用算子性能分析组件可以对MindSpore运行过程中的各个算子的执行时间进行统计展示(包括Ascend device算子、HOSTCPU算子)。
ASCEND算子:在Ascend上执行的算子,PyNative模式下不区分AICORE和AICPU算子。
HOSTCPU算子:Host侧CPU主要负责将图或者算子下发到昇腾芯片,根据实际需求也可以在Host侧CPU上开发算子。HOSTCPU算子特指运行在Host侧CPU上的算子。

图:算子类别统计分析
上图展示了按算子类别进行统计分析的结果,包含以下内容:
可以选择饼图/柱状图展示各算子类别的时间占比,每个算子类别的执行时间会统计属于该类别的算子执行时间总和。
统计前20个占比时间最长的算子类别,展示其时间所占的百分比以及具体的执行时间(毫秒)。
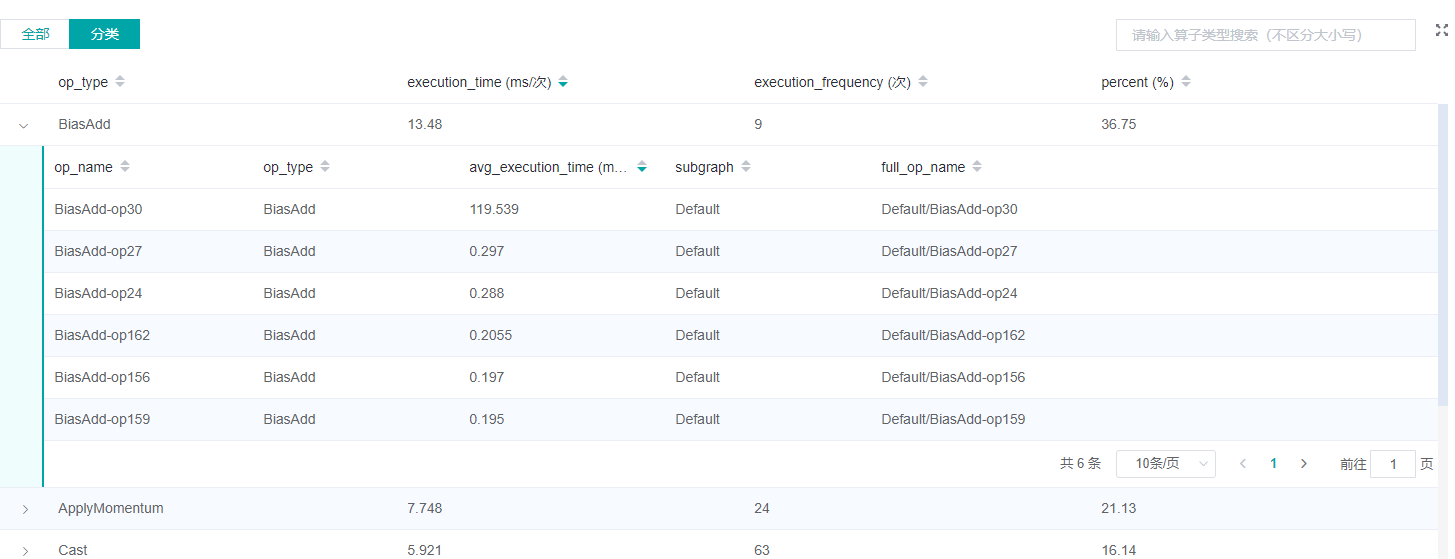
图:算子统计分析
上图展示了算子性能统计表,包含以下内容:
选择全部:按单个算子的统计结果进行排序展示,展示维度包括算子名称、算子类型、算子执行时间、子图、算子全scope名称;默认按算子执行时间排序。
选择分类:按算子类别的统计结果进行排序展示,展示维度包括算子分类名称、算子类别执行时间、执行频次、占总时间的比例等。点击每个算子类别,可以进一步查看该类别下所有单个算子的统计信息。
搜索:在右侧搜索框中输入字符串,支持对算子名称/类别进行模糊搜索。
数据准备性能分析
使用数据准备性能分析组件可以对训练数据准备过程进行性能分析。数据准备过程可以分为三个阶段:数据处理pipeline、数据发送至Device以及Device侧读取训练数据。数据准备性能分析组件会对每个阶段的处理性能进行详细分析,并将分析结果进行展示。
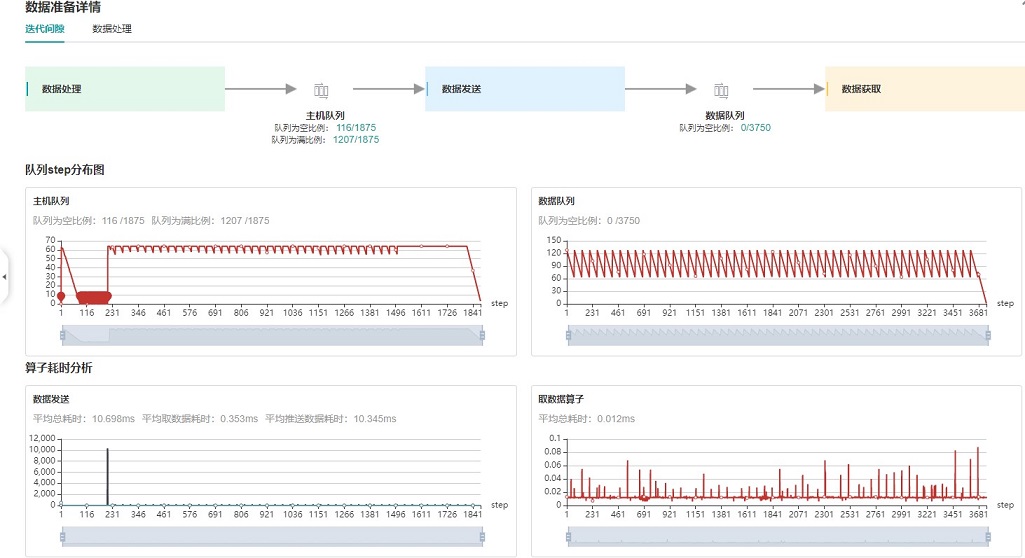
图:数据准备性能分析
上图展示了数据准备性能分析页面,包含迭代间隙、数据处理两个TAB页面。
迭代间隙TAB页主要用来分析数据准备三个阶段是否存在性能瓶颈,数据队列图是分析判断的重要依据:
数据队列Size代表Device侧从队列取数据时队列的长度,如果数据队列Size为0,则训练会一直等待,直到队列中有数据才会开始某个step的训练;如果数据队列Size大于0,则训练可以快速取到数据,数据准备不是该step的瓶颈所在。
主机队列Size可以推断出数据处理和发送速度,如果主机队列Size为0,表示数据处理速度慢而数据发送速度快,需要加快数据处理。
如果主机队列Size一直较大,而数据队列的Size持续很小,则数据发送有可能存在性能瓶颈。
说明
队列Size是取数据的时候记录的值,获取主机队列和数据队列数据是都异步执行,因此主机队列step数、数据队列step数、用户训练的step数都可能不一样。
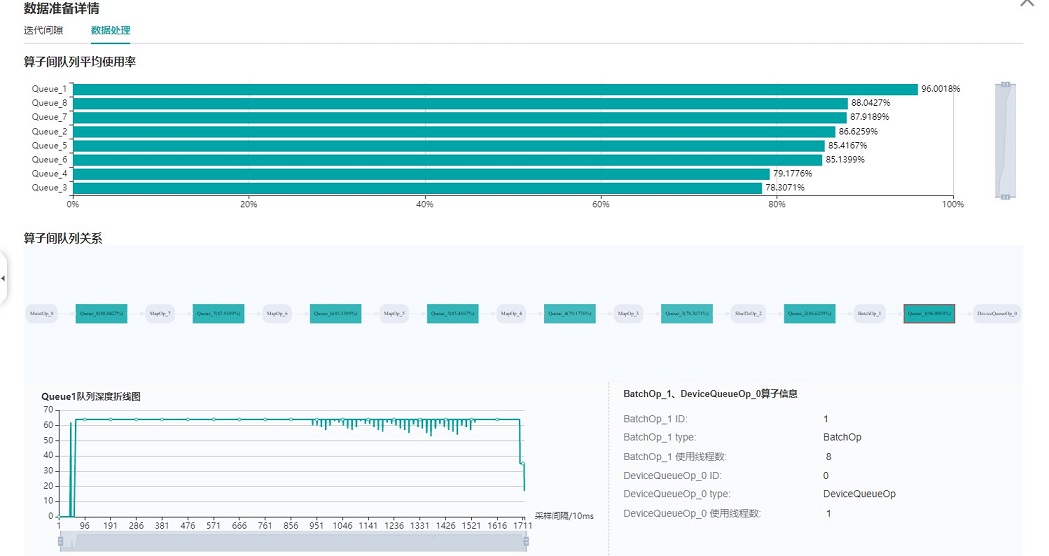
图:数据处理pipeline分析
上图展示了数据处理TAB页面,可以对数据处理pipeline做进一步分析。不同的数据算子之间使用队列进行数据交换,队列的长度可以反映出算子处理数据的快慢,进而推断出pipeline中的瓶颈算子所在。
算子队列的平均使用率代表队列中已有数据Size除以队列最大数据Size的平均值,使用率越高说明队列中数据积累越多。算子队列关系展示了数据处理pipeline中的算子以及它们之间的连接情况,点击某个队列可以在下方查看该队列中数据Size随着时间的变化曲线,以及与数据队列连接的算子信息等。对数据处理pipeline的分析有如下建议:
当算子左边连接的Queue使用率都比较高,右边连接的Queue使用率比较低,该算子可能是性能瓶颈。
对于最左侧的算子,如果其右边所有Queue的使用率都比较低,该算子可能是性能瓶颈。
对于最右侧的算子,如果其左边所有Queue的使用率都比较高,该算子可能是性能瓶颈。
对于不同的类型的数据处理算子,有如下优化建议:
如果Dataset算子是性能瓶颈,建议增加
num_parallel_workers。如果GeneratorOp类型的算子是性能瓶颈,建议增加
num_parallel_workers,并尝试将其替换为MindRecordDataset。如果MapOp类型的算子是性能瓶颈,建议增加
num_parallel_workers,如果该算子为Python算子,可以尝试优化脚本。如果BatchOp类型的算子是性能瓶颈,建议调整
prefetch_size的大小。
Timeline分析
Timeline组件可以展示:
算子分配到哪个设备(ASCEND、HOSTCPU)执行。
MindSpore对该网络的线程切分策略。
算子在Device上的执行序列和执行时长。
训练的Step数(只支持数据下沉场景)。
算子的
Scope Name信息,可以选择展示多少层Scope Name信息并下载对应的timeline文件。例如某算子的全名为:Default/network/lenet5/Conv2D-op11,则该算子的第一层Scope Name为Default、第二层为network。如果选择展示两层Scope Name信息,则会展示Default和network。
通过分析Timeline,用户可以定位到某个算子,查看分析他的执行时间。点击总览页面Timeline部分的下载按钮,可以将Timeline数据文件
(json格式) 保存至本地,再通过工具查看Timeline的详细信息。推荐使用
chrome://tracing 或者 Perfetto
做Timeline展示。
Chrome tracing:点击左上角“load”加载文件。
Perfetto:点击左侧“Open trace file”加载文件。

图:Timeline分析
Timeline主要包含如下几个部分:
Device及其stream list:包含Device上的stream列表,每个stream由task执行序列组成,一个task是其中的一个小方块,大小代表执行时间长短。
各个颜色块表示算子执行的起始时间及时长。timeline的详细解释如下:
Step:训练迭代数。
Ascend Op:在Ascend上执行的算子的时间线。
HOSTCPU Op:在HostCPU上执行的算子的时间线。
算子信息:选中某个task后,可以显示该task对应算子的信息,包括名称、type等。
可以使用W/A/S/D来放大、缩小地查看Timeline图信息。
规格
为了控制性能测试时生成数据的大小,大型网络建议性能调试的step数目限制在10以内。
说明
控制step数目可以通过控制训练数据集的大小来实现,如
mindspore.dataset.MindDataset类中的num_samples参数可以控制数据集大小,详情参考: mindspore.dataset.MindDataset 。Timeline数据的解析比较耗时,且一般几个step的数据即足够分析出结果。出于数据解析和UI展示性能的考虑,Profiler最多展示20M数据(对大型网络20M可以显示10+条step的信息)。
注意事项
训练加推理过程暂不支持性能调试,目前支持单独训练或推理的性能调试。
Ascend性能调试暂不支持动态shape场景、多子图场景和控制流场景。