大模型性能调优指南
![]()
性能调优概述
本文档主要介绍大语言模型的性能调优,详细介绍了性能调优相关的基础理论知识、相关工具使用指导和性能调优整体思路,以及案例分享。开始大模型性能调优工作时,应具备大模型的基础知识。为避免发散,本文档将不会解释大模型相关基础概念,聚焦性能调优介绍。
性能一般讨论的是模型训练性能,即在指定模型和输入数据的情况下,完成一次端到端训练所需要时间。端到端是指完成一个人工智能模型单步训练的过程,时间主要由以下部分构成:
数据加载时间:指的是模型加载训练数据和权重的时间,包括将数据从硬件存储设备读取到CPU、在CPU中进行数据的预处理、以及CPU数据传输到NPU的过程。对于需要切分到若干张NPU上的模型,数据加载时间还包括从一张NPU广播到其他NPU上的时间。
模型正向计算(Forward)反向计算(Backward)时间,包含前向的数据计算和反向的数据微分求导。
优化器时间:通常指的是模型参数更新时间。
模型后处理时间:指的是优化器更新后,包括数据的后处理或者必要的同步操作,通常取决于模型特定的操作。
通信时间:概念比较宽泛,涵盖单节点的卡间通信耗时和多节点的节点间通信耗时。通过MindSpore的并行技术,通信和计算通常可以并行执行,此时部分通信时间会被掩盖,因此一般考虑未被计算掩盖的通信时间。
调度时间:指模型从CPU指令到调用NPU内核所需要的时间。
性能调优旨在通过优化模型算法、参数和并行策略等手段,降低上述各部分时间,一般重点关注模型前向反向时间以及通信时间进行优化。
性能调优基础简介
性能指标
性能通常通过吞吐量指标进行评估,对于大语言模型,吞吐量主要是指每秒钟每张卡处理的token数量。计算公式如下:
(sample/s/p)的计算结果可以直接从日志中获取,也可以从日志中分别获取对应字段再进行计算。
各字段含义如下:
SeqLength:指序列的长度,在文本处理过程中,输入的文本需要转换成数字序列,这些数字序列作为模型的输入。SeqLength就是指这些数字序列的长度,即文本的长度。在模型训练和推理的过程中,需要设置一个固定的SeqLength,以便进行批处理和计算。较长的SeqLength可以提高模型的准确性,但会增加计算量和内存消耗;而较短的SeqLength则会减少计算量和内存消耗,但可能会降低模型的准确性。
sample:其值等于全局批量大小,即global_batch_size的值。在分布式训练中,数据被分成多个部分,每个部分被送到不同的NPU上进行计算。这些NPU上的Batch Size之和就是全局批量大小。全局批量大小的选择是一个重要的决策,因为它会直接影响模型的训练性能。如果全局批量过小,每个NPU上的Batch Size可能会太小,导致模型的收敛速度变慢;如果全局批量过大,每个NPU上的Batch Size可能会太大,导致NPU内存不足或者模型的精度下降。一个找到最佳Batch Size的经验法则是使其达到NPU对给定数据类型的内存限制,即Batch Size占满NPU内存。
s:即per_step_time,以秒为单位,指在训练过程中,每一步所花费的时间。
p:即parallel_num,指数据并行维度大小。
并行特性简介
在大模型训练中,由于数据量和模型复杂度的增加,单个计算节点的计算能力往往难以满足训练的需求。为了提高训练效率和加速训练过程,通常采用并行策略将计算任务分配给多个计算节点。
并行策略通常分为以下几种:
数据并行(Data Parallelism,简称DP)
模型并行(一般指张量并行Tensor Parallelism,简称TP)
流水并行(Pipeline Parallelism,简称PP)
优化器并行(Optimizer Parallelism,简称OP)
序列并行(Sequence Parallelism,简称SP)
多副本并行
在实际应用中,通常会采用多种并行策略和优化手段,例如使用优化器并行和重计算等方式,以减少模型对内存的使用并提高训练效率。并行策略设计与模型的效率密切相关,因此在模型调优之前先确定一组或多组较优的并行策略,是至关重要的。
详细介绍参考文档并行策略指南。
重计算
MindSpore采用反向模式的自动微分,根据正向图计算流程自动推导出反向图,正向图和反向图共同构成了完整的计算图。在计算某些反向算子时,需要使用一些正向算子的计算结果,导致这些计算结果需要保存在内存中,直到依赖它们的反向算子计算完成,占用的内存才会被复用。这一现象提高了训练的内存峰值,在大规模网络模型中尤为显著。
为了解决这个问题,MindSpore提供了重计算的功能,可以不保存正向算子的计算结果,从而释放内存以供复用。在计算反向算子时,如果需要正向的结果,再重新计算正向算子。
重计算分为以下两种方式:
完全重计算
适用于内存资源极为受限的极端环境。在这种模式下,除了保存输入数据外,所有激活值均在需要时重新计算,最大限度地减少了对内存的依赖,然而计算量也会显著增加。
选择性重计算
该策略保留了那些占用较小内存空间但重计算成本较高的激活值,如Cast、SiLU-Mul。同时,对占用较大内存但重计算成本相对较低的激活值执行重计算。此方法在保证模型性能的同时,实现了内存使用的高效管理。
Cast重计算
RMSNorm一般使用高精度(FP32)计算,计算之前需要将输入从低精度(FP16或BF16)通过Cast转成高精度(FP32)。RMSNorm需要保存输入以用于反向计算。因此对Cast进行重计算可以只保存Cast的低精度输入,而非高精度输入,从而可以减少一半的内存占用,达到节省内存的效果。
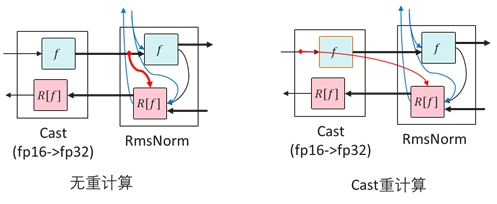
然而从高精度到低精度的Cast算子进行重计算,会导致后面的算子原本只需要保存Cast之后的低精度内存,但是由于Cast算子重计算,需要保存高精度内存,反而会导致内存占用增加。
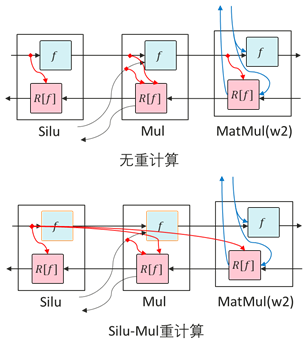
SiLU-Mul重计算
在FeedForward中,中间部分内存占用通常较大。由于SiLU和Mul重计算代价较小,对SiLU和Mul算子重计算,可以省下w2的MatMul和Mul的第一个输入的内存。
工具介绍
profiler工具
MindFormers本身集成了profiling数据采集的功能,使用步骤如下:
修改配置文件
在模型的配置文件中开启profiling开关,需修改的参数如下:
profile: True #是否开启性能分析工具 profile_start_step: 5 #性能分析开始的step profile_stop_step: 6 #性能分析结束的step init_start_profile: False #Profiler初始化的时候开启,开启后profile_start_step将不生效。 profile_communication: False #是否在多NPU训练中收集通信性能数据 profile_memory: True #收集Tensor内存数据
profile_start_step和profile_stop_step用于确定采集区间,因为采集耗时较长,不推荐将区间设置过大,建议设置为2到4步。且由于第一个step涉及编译,推荐从第3步开始采集。
查看数据
采集工具默认会在
./output路径下创建一个profile文件夹,该路径可通过模型yaml配置文件的output_dir字段进行设置。生成的文件及介绍参考profile文件介绍,主要收集算子、任务等运行耗时、CPU利用率及内存消耗等信息,用于性能调优分析。
MindStudio Insight
MindStudio Insight提供了性能数据的多种呈现形式,包括Timeline视图、通信分析和计算耗时等可视化呈现,以便用户分析潜在的性能瓶颈,并指导如何采取措施消除或减少这些瓶颈。MindStudio Insight支持在Timeline视图中查看集群场景下Profiling导出的数据,并以单卡为维度进行展示,可以支持20GB以上的集群性能文件分析。
点击MindStudio Insight下载链接,选择合适的版本安装。
打开MindStudio Insight工具,单击界面左上方工具栏中的“+”,在弹窗中选择要解析并导出的文件或目录,然后单击“确认”导入。
MindStudio Insight工具以时间线(Timeline)的形式呈现全流程在线推理、训练过程中的运行情况,并按照调度流程来呈现整体的运行状况,并且该工具支持集群Timeline展示。通过分析时间线,用户可以对在线推理/训练过程进行细粒度的分析,如迭代间隙是否过长、算子执行时间等,并提供易用性功能辅助用户快速定位性能瓶颈。
时间线(Timeline)界面包含工具栏(区域一)、时间线树状图(区域二)、图形化窗格(区域三)和数据窗格(区域四)四个部分,如图所示。
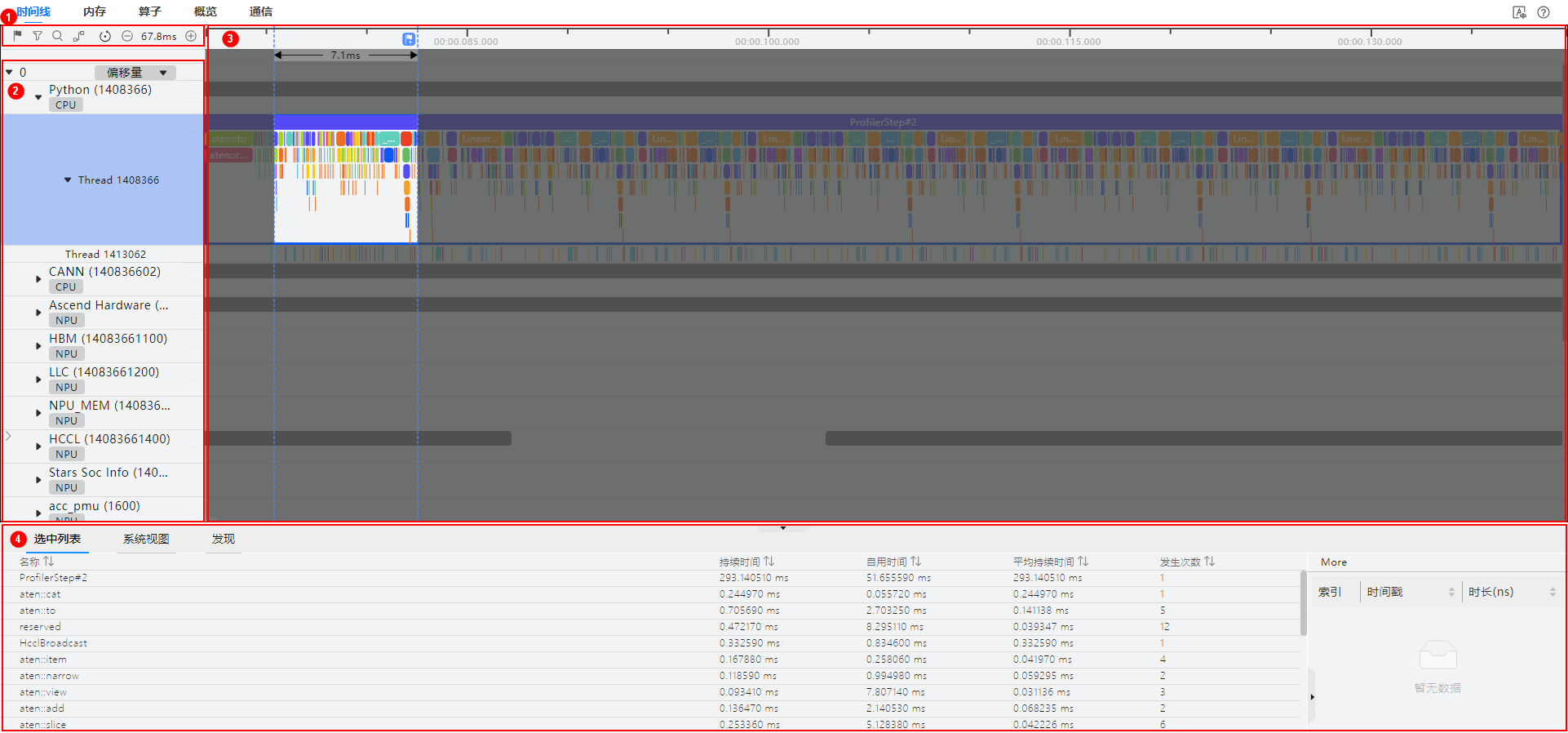
区域一
工具栏,包含常用快捷按钮,从左至右依次为标记列表、过滤(支持按卡或按专项层过滤展示)、搜索、连线事件、复原、时间轴缩小和时间轴放大。
区域二
时间线树状图,显示集群场景下各“Card”的分层信息,一层级为“Card”,二层级为进程或专项分层,三层级为线程等。包括上层应用数据(包含上层应用算子的耗时信息)、CANN层数据(包含AscendCL、GE和Runtime组件的耗时数据)、底层NPU数据(包含Ascend Hardware下各个Stream任务流的耗时数据和迭代轨迹数据、HCCL和Overlap Analysis通信数据以及其他昇腾AI处理器系统数据)、打点数据和AI Core Freq层级。
区域三
图形化窗格,展示的数据是迭代内的数据,图形化窗格对应时间线树状图,逐行对时间线进行图形化展现,包括上层应用算子、各组件及接口的执行序列和执行时长。
区域四
数据窗格,统计信息或算子详情信息展示区,选中详情(Slice Detail)为选中单个算子的详细信息,选中列表(Slice List)为某一泳道选中区域的算子列表信息,系统视图(System View)为某类算子的汇总信息。
单击时间线页面树状图或者图形化窗格任意位置,可以使用键盘中的W(放大)、A(左移)、S(缩小)、D(右移)键进行操作,支持放大的最大精度为1ns。本工具可以提供概览、内存、算子、通信等多个维度的分析,辅助进行性能调优。详细使用方法参考MindStudio Insight用户指南。
IR 图
在MindFormers配置文件中,只需要开启save_graphs,运行时会输出一些图编译过程中生成的.ir后缀的中间文件,这些被称为IR文件。默认情况下,这些文件会保存在当前执行目录下的graph目录中。IR文件是一种比较直观易懂的文本格式文件,用于描述模型结构的文件,可以直接用文本编辑软件查看。配置项含义参考Config配置说明,配置方法如下:
context:
save_graphs: True
save_graphs_path: "./graph"
以下是部分IR图的节选:
%13(equiv_180_CNode_16165) = Load(%para6_model.layers.0.attention.wq.weight, UMonad[U]) cnode_attrs: {checkpoint: Bool(1)} cnode_primal_attrs: {unique_id: "782039"}
: (<Ref[Tensor[Float16]], (512, 4096), ref_key=model.layers.0.attention.wq.weight>, <UMonad, NoShape>) -> (<Tensor[Float16], (512, 4096)>)
# Fullname with scope: (Default/network-MFPipelineWithLossScaleCell/network-_VirtualDatasetCell/_backbone-GradAccumulationCell/network-LlamaForCausalLM/model-LlamaModel/layers-CellList/0-LLamaDecodeLayer/attention-LLamaAttention/Load-op0)
%14(equiv_16877_x) = PrimFunc_MatMul(%12, %13, Bool(0), Bool(1)) {instance name: matmul} primitive_attrs: {in_strategy: ((1, 1), (8, 1))} cnode_attrs: {checkpoint: Bool(1)} cnode_primal_attrs: {unique_id: "782146", origin_output_shape: (4096, 4096), micro: I64(0), origin_input_shapes: ((4096, 4096), (4096, 4096))} {in_strategy: ((1, 1), (8, 1))}
: (<Tensor[Float16], (4096, 4096)>, <Tensor[Float16], (512, 4096)>, <Bool, NoShape>, <Bool, NoShape>) -> (<Tensor[Float16], (4096, 512)>)
# Fullname with scope: (Default/network-MFPipelineWithLossScaleCell/network-_VirtualDatasetCell/_backbone-GradAccumulationCell/network-LlamaForCausalLM/model-LlamaModel/layers-CellList/0-LLamaDecodeLayer/attention-LLamaAttention/wq-Linear/MatMul-op0)
%15(equiv_16876_CNode_30913) = PrimFunc_Reshape(%14, (I64(1), I64(4096), I64(4), I64(128))) {instance name: reshape} cnode_attrs: {checkpoint: Bool(1)} cnode_primal_attrs: {unique_id: "817859", forward_comm_node_unique_id: "729440", micro: I64(0)}
: (<Tensor[Float16], (4096, 512)>, <Tuple[Int64*4], TupleShape(NoShape, NoShape, NoShape, NoShape), elements_use_flags={[const vector]{1, 1, 1, 1}}>) -> (<Tensor[Float16], (1, 4096, 4, 128)>)
# Fullname with scope: (Default/network-MFPipelineWithLossScaleCell/network-_VirtualDatasetCell/_backbone-GradAccumulationCell/network-LlamaForCausalLM/model-LlamaModel/layers-CellList/0-LLamaDecodeLayer/attention-LLamaAttention/Reshape-op0)
%16(equiv_16875_query) = PrimFunc_Transpose(%15, (I64(0), I64(2), I64(1), I64(3))) {instance name: transpose} primitive_attrs: {in_strategy: ((1, 1, 8, 1))} cnode_attrs: {checkpoint: Bool(1)} cnode_primal_attrs: {unique_id: "782042", micro: I64(0)} {in_strategy: ((1, 1, 8, 1))}
: (<Tensor[Float16], (1, 4096, 4, 128)>, <Tuple[Int64*4], TupleShape(NoShape, NoShape, NoShape, NoShape), elements_use_flags={[const vector]{1, 1, 1, 1}}>) -> (<Tensor[Float16], (1, 4, 4096, 128)>)
# Fullname with scope: (Default/network-MFPipelineWithLossScaleCell/network-_VirtualDatasetCell/_backbone-GradAccumulationCell/network-LlamaForCausalLM/model-LlamaModel/layers-CellList/0-LLamaDecodeLayer/attention-LLamaAttention/Transpose-op0)
%XX 表示步骤,后面对应算子名称,括号内包含入参及输出。Fullname with scope则包含了完成的class、方法名等信息。
%13此步直接加载wq.weight,得到<Tensor[Float16], (512, 4096)>。
%14将前面的%12输出与%13输出进行MatMul操作,得到<Tensor[Float16], (4096, 512)>。
%15将上述14%的输出进行Reshape操作得到<Tensor[Float16], (1, 4096, 4, 128)>。
%16将上述15%的输出进行Transpose操作得到<Tensor[Float16], (1, 4, 4096, 128)>。
SAPP自动负载均衡工具
大模型训练性能调优需要同时考虑多维混合并行策略配置与内存限制,工程师需要在集群上尝试不同的组合方案,才能找到性能达标的并行策略,这一过程常常耗费数周时间,且消耗大量算力成本。
MindSpore提供了SAPP(Symbolic Automatic Parallel Planner)自动负载均衡工具。只需输入模型的内存和时间信息,以及部分流水线并行性能相关的超参(如重计算对性能的影响),工具将自行构建线性规划问题,通过全局求解的方式,为大模型自动生成流水线并行中的stage-layer配比,调整各layer重计算策略,自动优化集群算力和内存利用率,降低空等时间,实现Pipeline并行分钟级策略寻优,大幅度降低性能调优成本,显著提升端到端训练性能。
详细使用方法,请参考SAPP流水线负载均衡工具介绍。
性能调优整体思路
整体思路
大模型的性能调优主要包含并行策略配置、内存优化、耗时分析三部分工作。性能优化是一个循环往复的过程,并行策略配置完毕后,就需要进行内存优化分析及优化,然后对集群分布式策略进行实验分析,分析通信耗时是否合理,是否存在额外的重排布开销。最后根据分析结果,调整并行策略,继续内存、耗时分析,循环往复的去优化,进而一步步达到设定的性能目标。
完成一轮性能优化后,还需要确保模型精度对齐,若对齐则应用该优化策略。
并行策略
并行策略特点
不同的并行策略特点总结如下:
数据并行
多路数据同时训练,仅在梯度更新时进行一次通信,此方法性能最优,但内存不会减少。
模型并行
将整个模型切分到不同Device中,网络并行计算各自部分,并在LayerNorm等位置进行通信,此方法最省内存,但通信量很大。
流水线并行
将模型的不同阶段(stage)切分到不同Device中,网络串行计算各个阶段并在转换阶段时进行通信,通过重计算节省部分内存,此方法通信量较小,但会存在计算闲置(bubble)。
优化器并行
将优化器权重、模型权重按DP切分(DP能整除权重shape的第0维),梯度更新时进行通信,此方法可以明显节省内存,通信量较小。
序列并行
短序列并行在LayerNorm处对序列按MP进行切分,通信量不变,减少内存与Norm的部分计算量;
多副本并行
在模型并行中,将MatMul等算子切分为多份,不同副本之间计算和通信交错进行,实现通信掩盖。
使用建议
实际应用中,通常是多种并行策略组合使用。根据模型规模,机器数量确定适当的并行策略。本节介绍不同规模模型的推荐配置,示例配置中各配置项含义参考Config配置说明。
小参数模型
模型规模较小时(如7B),可使用纯数据并行+优化器并行,如果内存富裕可进一步开启梯度累积。使用8卡训练,Llama2-7B并行策略推荐配置。
中等参数模型
模型规模适中时(如13B),可进一步使用流水线并行,并调整重计算。使用8卡训练,Llama2-13B并行策略推荐配置。
大参数模型
模型规模较大时(如70B),需开启模型并行,同时序列并行与多副本并行也建议开启。使用64卡训练,Llama2-70B并行策略推荐配置。
内存优化
模型训练过程中,计算资源是有限的,内存不足时需要开重计算。内存优化主要优化重计算的配置,可以借助上述SAPP工具,自动生成当前并行配置下的推荐重计算配置。
MindSpore还提供DryRun功能,能够在本地环境模拟大集群中每个rank的内存消耗情况,从而在不依赖实际大集群资源的情况下,进行高效的设备内存模拟。
完成重计算配置后,先使用DryRun分析所需内存是否超过最大可用内存。如果超过,需要重新调整配置。最大可用内存可通过如下字段配置,推荐值为58GB,如果设置过大,可能导致其他组件内存不足。
context:
max_device_memory: "58GB"
新建脚本dry_run.sh,脚本内容如下:
#!/bin/bash
YAML_FILE=$1
RANK_SIZE=$2
PIPELINE_STAGES=$3
RANK_GAP=$((RANK_SIZE/PIPELINE_STAGES))
ROOT_PATH=`pwd`
export MS_SIMULATION_LEVEL=1
export RANK_SIZE=$RANK_SIZE
rm -rf output_dryrun
mkdir output_dryrun
for((i=0; i<$PIPELINE_STAGES; i++))
do
export DEVICE_ID=$i
export RANK_ID=$((i*RANK_GAP))
echo "start training for rank $RANK_ID, device $DEVICE_ID"
# 需要正确指定 run_mindformer.py 路径
python ./run_mindformer.py --config $ROOT_PATH/$1 &> ./output_dryrun/rank_$RANK_ID.log &
done
执行脚本
bash dry_run.sh $train.yaml $rank_size $stage
三个参数含义如下:
$train.yaml:需要调试的配置文件
$rank_size:模拟卡数
$stage:阶段数,等于流水线并行数量
执行完成后,输出目录output_dryrun下会生成每个stage的日志信息,每个日志末尾会打印如下信息。
Device MOC memory size: 62432M
MindSpore Used memory size: 59392M
MindSpore memory base address: 0
Used peak memory usage (without fragments): 48874M
Actual peak memory usage (with fragments): 48874M
Used peak memory usage (without fragments):表示不包含碎片的NPU内存使用峰值,重点关注该值,建议不超过最大可用内存。
Actual peak memory usage (with fragments):表示包含碎片的NPU内存使用峰值。
耗时分析
耗时主要分为算子耗时以及通信耗时两部分,依赖于profiling数据分析,分析方法参考上述章节。重点分析任意rank的profiler文件夹下ascend_timeline_display_0.json和rank-*_ascend_ms/ASCEND_PROFILER_OUTPUT/kernel_details.csv两个文件。
使用上述章节提到的MindStudio Insight工具解析ascend_timeline_display_0.json,统计分析计算、通信耗时是否符合预期,再查看kernel_details.csv,分析各算子详细情况。
典型案例
SiLU-Mul重计算未生效
在开启细粒度多副本时,对SiLU和Mul做重计算可以节省内存,但关闭细粒度多副本时,对SiLU和Mul做重计算不能节省内存。定位过程如下:
确认配置了重计算
在IR图中检查Cast、SiLU和Mul算子是否有“recompute: Bool(1)”的标签,如果有标签说明算子配置了重计算。
检查重计算生效算子
在IR图中检查Cast、SiLU和Mul等算子是否有duplicated标签,没有带标签的算子说明实际计算图没有重计算这部分算子。如下示例只有Cast算子带了duplicated标签。
%1834(CNode_108839) = PrimFunc_Cast(%1833, I64(43)) {instance name: cast} primitive_attrs: {output_names: [output], input_names: [x, dst_type], recompute: Bool(1)} cnode_attrs: {recompute_sub_graph: U64(64), recompute_id: I64(65), duplicated: Bool(1), need_cse_after_recompute: Bool(1)} cnode_primal_attrs: {micro: I64(0)} : (<Tensor[Float16], (1, 4096, 4096)>, <Int64, NoShape>) -> (<Tensor[Float32], (1, 4096, 4096)>)检查反向计算输入
在IR图中检查SiLU和Mul的反向算子的输入是否符合预期,在关闭细粒度多副本时,SiLU和Mul之间、Mul和MatMul之间均有Reshape算子,而开启细粒度多副本时,SiLU、Mul和MatMul是相连的。绘制相关流程如下:
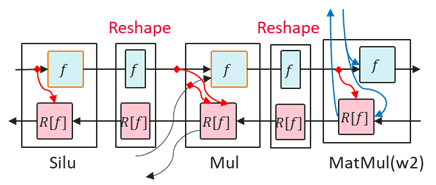
由此可知根因在于,细粒度多副本场景中Linear的输入shape是二维的,而非细粒度多副本中Linear的输入shape是三维的,所以Linear和Mul之间有Reshape算子,没对这个Reshape算子重计算导致对SiLU的重计算没有生效。额外对Reshape重计算后内存可以正常减小。参考配置如下:
recompute_config:
recompute: False
select_recompute: ['feed_forward\.mul', 'feed_forward\.w1\.activation', 'feed_forward\.w1\.reshape', 'feed_forward\.w2\.reshape']
Llama2-13B极致性能优化
13B默认用单机DP: 8, MP: 1, PP: 1,开完全重计算,性能在1860tokens/s/p左右,相较于7B(2465tokens/s/p)与70B(1974tokens/s/p),性能明显偏低。
经分析,13B性能瓶颈主要在于内存,无论是单机还是多机,如果不开MP,对SiLU和Mul做选择重计算内存依然不够,则需要开完全重计算。完全重计算会额外多20%到25%的计算量,导致性能偏低。
经过实测,开MP关闭重计算,性能比纯DP还要低。双机并行策略调整为DP: 8, MP: 1, PP: 2, micro: 128,开完全重计算,性能提升至2136tokens/s/p。将完全重计算改为选择重计算,并精细选择算子,使每层的内存尽可能减少,性能提升至2189tokens/s/p。
select_recompute: ['feed_forward\.mul', 'feed_forward\.w1\.activation', 'feed_forward\.w1\.reshape', 'feed_forward\.w1\.matmul', 'feed_forward\.w3\.matmul', 'feed_forward\.W3\.reshape', 'feed_forward\.w2\.matmul', 'feed_forward\.w2\.reshape', 'ffn_norm\.norm', 'ffn_norm\.rcast', 'attention_norm\.norm', 'attention_norm\.rcast', 'attention\.wq\.reshape', 'attention\.wk\.reshape', 'attention\.wv\.reshape', 'attention\.wo\.matmul', 'attention\.wo\.reshape', 'attention\.merger_head_transpose', 'add', 'attention\.flash attention']
调整不同stage的重计算层数,使stage1的重计算量减少,性能提升至2210tokens/s/p。
select_recompute:
'feed_forward\.mul': [20, 8]
'feed_forward\.w1\.activation': [20, 8]
'feed_forward\.w1\.matmul': [20, 0]
'feed_forward\.w1\.reshape': [20, 8]
'feed_forward\.w3\.matmul': [20, 0]
'feed_forward\.w3\.reshape': [20, 0]
'feed_forward\.w2\.matmul': [20, 0]
'feed_forward\.w2\.reshape': [20, 0]
'ffn_norm\.norm': [20, 0]
'ffn_norm\.rcast': [20, 0]
'attention_norm\.norm': [20, 0]
'attention_normi.rcast': [20, 0]
'attention\.wq\.reshape': [20, 0]e
'attention\.wk\.reshape': [20, 0]e
'attention\.w\.reshape': [20, 0]e
'attention\.wol.matmul': [20, 0]
'attention\.wo\.reshape': [20, 0]e
'attention\.merger head transpose': [20, 0]
'add': [20, 0]
'attention\.flash_attention': [20, 0]
使用图编译等级为O0/O1图算融合,内存有进一步优化,将大部分算子的选择重计算改为部分层的完全重计算,其余层配置SiLU和Mul的选择重计算,stage0、stage1分别完全重计算13层、5层,性能提升至2353tokens/s/p。逐步减少stage0、stage1完全重计算至4层、0层,性能提升至2562tokens/s/p(max_device_memory: 57.2GB)。参考配置如下:
recompute_config:
recompute: [4, 0]
select_recompute: ['feed_forward\.mul', 'feed_forward\.w1\.activation', 'feed_forward\.w1\.reshape', 'feed_forward\.w2\.reshape']
最终经过调优后,Llama2-13B性能优化至2562tokens/s/p,总计提升37%。