FuXi: 基于级联架构的全球中期天气预报
![]()
![]()
![]()
概述
FuXi模型是由复旦大学的研究人员开发的一个基于数据驱动的全球天气预报模型。它提供了关键全球天气指标的中期预报,分辨率为0.25°。相当于赤道附近约25公里 x 25公里的空间分辨率和大小为720 x 1440像素的全球网格。与以前的基于MachineLearning的天气预报模型相比,采用级联架构的FuXi模型在EC中期预报评估中取得了优异的结果。
本教程介绍了FuXi的研究背景和技术路径,并展示了如何通过MindSpore Earth训练和快速推理模型。更多信息参见文章。本教程中使用分辨率为0.25°的ERA5_0_25_tiny400数据集,详细介绍案例的运行流程。
FuXi
基本的伏羲模型体系结构由三个主要组件组成,如图所示:Cube Embedding、U-Transformer和全连接层。输入数据结合了上层空气和地表变量,并创建了一个维度为69×720×1440的数据立方体,以一个时间步作为一个step。
高维输入数据通过联合时空Cube Embedding进行维度缩减,转换为C×180×360。Cube Embedding的主要目的是减少输入数据的时空维度,减少冗余信息。随后,U-Transformer处理嵌入数据,并使用简单的全连接层进行预测,输出首先被重塑为69×720×1440。
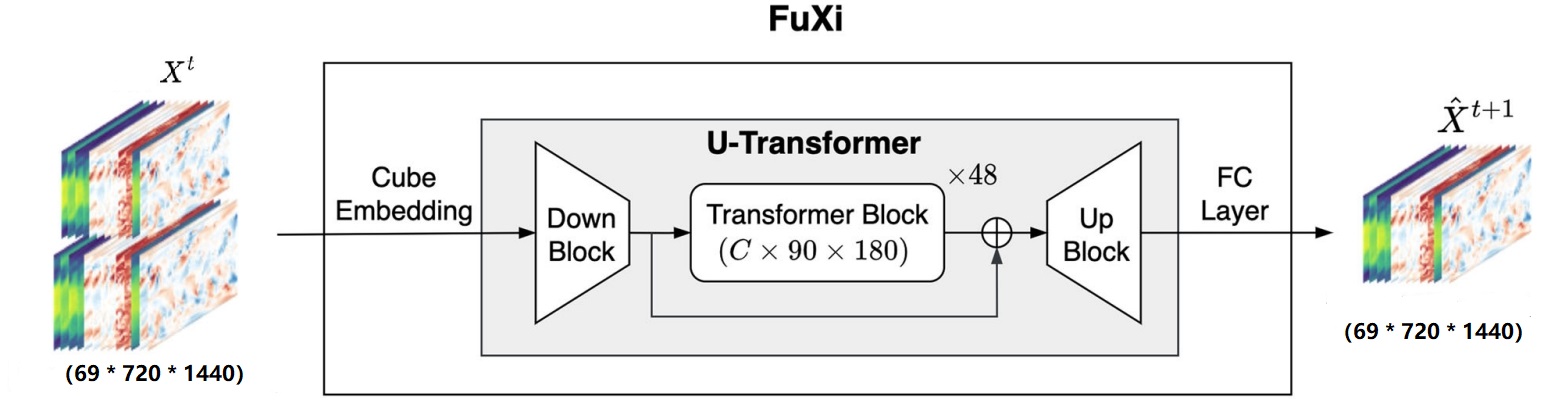
Cube Embedding
为了减少输入数据的空间和时间维度,并加快训练过程,应用了Cube Embedding方法。
具体地,空时立方体嵌入采用了一个三维(3D)卷积层,卷积核和步幅分别为2×4×4(相当于
U-Transformer
U-Transformer还包括U-Net模型的下采样和上采样块。下采样块在图中称为Down Block,将数据维度减少为C×90×180,从而最小化自注意力计算的计算和内存需求。Down Block由一个步长为2的3×3 2D卷积层和一个残差块组成,该残差块有两个3×3卷积层,后面跟随一个组归一化(GN)层和一个Sigmoid加权激活函数(SiLU)。SiLU加权激活函数通过将Sigmoid函数与其输入相乘来计算
上采样块在图中称为Up Block,它与Down Block使用相同的残差块,同时还包括一个2D反卷积,内核为2,步长为2。Up Block将数据大小缩放回
中间结构是由18个重复的Swin Transformer块构建而成,通过使用残差后归一化代替前归一化,缩放余弦注意力代替原始点积自注意力,Swin Transformer解决了诸如训练不稳定等训练和应用大规模的Swin Transformer模型会出现几个问题。
技术路径
MindSpore Earth求解该问题的具体流程如下:
创建数据集
模型构建
损失函数
模型训练
模型评估与可视化
[2]:
import os
import random
import matplotlib.pyplot as plt
import numpy as np
from mindspore import set_seed
from mindspore import context
from mindspore import load_checkpoint, load_param_into_net
下述src可以在fuxi/src下载。
[3]:
from mindearth.utils import load_yaml_config, plt_global_field_data, make_dir
from mindearth.data import Dataset, Era5Data
from src import init_model, get_logger
from src import MAELossForMultiLabel, FuXiTrainer, CustomWithLossCell, InferenceModule
[4]:
set_seed(0)
np.random.seed(0)
random.seed(0)
可以在配置文件中配置模型、数据和优化器等参数。
[5]:
config = load_yaml_config("configs/FuXi.yaml")
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", device_id=0)
创建数据集
下载ERA5_0_25_tiny400数据集到./dataset目录。
./dataset中的目录结构如下所示:
.
├── statistic
│ ├── mean.npy
│ ├── mean_s.npy
│ ├── std.npy
│ ├── std_s.npy
│ └── climate_0.25.npy
├── train
│ └── 2015
├── train_static
│ └── 2015
├── train_surface
│ └── 2015
├── train_surface_static
│ └── 2015
├── valid
│ └── 2016
├── valid_static
│ └── 2016
├── valid_surface
│ └── 2016
├── valid_surface_static
│ └── 2016
模型构建
模型初始化主要包括Swin Transformer Block数目以及训练参数。
[6]:
make_dir(os.path.join(config['summary']["summary_dir"], "image"))
logger_obj = get_logger(config)
fuxi_model = init_model(config, "train")
2024-01-29 12:34:41,485 - utils.py[line:91] - INFO: {'name': 'FuXi', 'depths': 18, 'in_channels': 96, 'out_channels': 192}
2024-01-29 12:34:41,487 - utils.py[line:91] - INFO: {'name': 'era5', 'root_dir': '/data4/cq/ERA5_0_25/', 'feature_dims': 69, 'pressure_level_num': 13, 'level_feature_size': 5, 'surface_feature_size': 4, 'h_size': 720, 'w_size': 1440, 'data_sink': False, 'batch_size': 1, 't_in': 1, 't_out_train': 1, 't_out_valid': 20, 't_out_test': 20, 'train_interval': 6, 'valid_interval': 6, 'test_interval': 6, 'pred_lead_time': 6, 'data_frequency': 6, 'train_period': [2015, 2015], 'valid_period': [2016, 2016], 'test_period': [2017, 2017], 'num_workers': 1, 'grid_resolution': 0.25}
2024-01-29 12:34:41,488 - utils.py[line:91] - INFO: {'name': 'adam', 'initial_lr': 0.00025, 'finetune_lr': 1e-05, 'finetune_epochs': 1, 'warmup_epochs': 1, 'weight_decay': 0.0, 'loss_weight': 0.25, 'gamma': 0.5, 'epochs': 100}
2024-01-29 12:34:41,489 - utils.py[line:91] - INFO: {'summary_dir': './summary', 'eval_interval': 10, 'save_checkpoint_steps': 10, 'keep_checkpoint_max': 50, 'plt_key_info': True, 'key_info_timestep': [6, 72, 120], 'ckpt_path': '/data3/cq'}
2024-01-29 12:34:41,490 - utils.py[line:91] - INFO: {'name': 'oop', 'distribute': False, 'amp_level': 'O2', 'load_ckpt': True}
损失函数
FuXi在模型训练中使用自定义平均绝对误差。
[10]:
data_params = config.get('data')
optimizer_params = config.get('optimizer')
loss_fn = MAELossForMultiLabel(data_params=data_params, optimizer_params=optimizer_params)
loss_cell = CustomWithLossCell(backbone=fuxi_model, loss_fn=loss_fn)
模型训练
在本教程中,我们继承了Trainer并重写了get_solver成员函数来构建自定义损失函数,并重写了get_callback成员函数来在训练过程中对测试数据集执行推理。
MindSpore Earth提供训练和推理接口,使用2.0.0及之后的MindSpore训练网络。
[15]:
trainer = FuXiTrainer(config, fuxi_model, loss_cell, logger_obj)
trainer.train()
2023-12-29 08:46:01,280 - pretrain.py[line:215] - INFO: steps_per_epoch: 67
epoch: 1 step: 67, loss is 0.37644267
Train epoch time: 222879.994 ms, per step time: 3326.567 ms
epoch: 2 step: 67, loss is 0.26096737
Train epoch time: 216913.275 ms, per step time: 3237.512 ms
epoch: 3 step: 67, loss is 0.2587443
Train epoch time: 217870.765 ms, per step time: 3251.802 ms
epoch: 4 step: 67, loss is 0.2280185
Train epoch time: 218111.564 ms, per step time: 3255.396 ms
epoch: 5 step: 67, loss is 0.20605856
Train epoch time: 216881.674 ms, per step time: 3237.040 ms
epoch: 6 step: 67, loss is 0.20178188
Train epoch time: 218800.354 ms, per step time: 3265.677 ms
epoch: 7 step: 67, loss is 0.21064804
Train epoch time: 217554.571 ms, per step time: 3247.083 ms
epoch: 8 step: 67, loss is 0.20392722
Train epoch time: 217324.330 ms, per step time: 3243.647 ms
epoch: 9 step: 67, loss is 0.19890495
Train epoch time: 218374.032 ms, per step time: 3259.314 ms
epoch: 10 step: 67, loss is 0.2064792
Train epoch time: 217399.318 ms, per step time: 3244.766 ms
2023-12-29 09:22:23,927 - forecast.py[line:223] - INFO: ================================Start Evaluation================================
2023-12-29 09:24:51,246 - forecast.py[line:241] - INFO: test dataset size: 1
2023-12-29 09:24:51,248 - forecast.py[line:191] - INFO: t = 6 hour:
2023-12-29 09:24:51,250 - forecast.py[line:202] - INFO: RMSE of Z500: 313.254855370194, T2m: 2.911020155335285, T850: 1.6009748653510902, U10: 1.8822629694594444
2023-12-29 09:24:51,251 - forecast.py[line:203] - INFO: ACC of Z500: 0.9950579247892839, T2m: 0.98743929296225, T850: 0.9930489273077082, U10: 0.9441216196638477
2023-12-29 09:24:51,252 - forecast.py[line:191] - INFO: t = 72 hour:
2023-12-29 09:24:51,253 - forecast.py[line:202] - INFO: RMSE of Z500: 1176.8557892319443, T2m: 7.344694139181644, T850: 6.165706260104667, U10: 5.953978905254709
2023-12-29 09:24:51,254 - forecast.py[line:203] - INFO: ACC of Z500: 0.9271318752961824, T2m: 0.9236962494086007, T850: 0.9098796075852417, U10: 0.5003382663349598
2023-12-29 09:24:51,255 - forecast.py[line:191] - INFO: t = 120 hour:
2023-12-29 09:24:51,256 - forecast.py[line:202] - INFO: RMSE of Z500: 1732.662048442734, T2m: 9.891472332990181, T850: 8.233521390723434, U10: 7.434774900830313
2023-12-29 09:24:51,256 - forecast.py[line:203] - INFO: ACC of Z500: 0.8421506711992445, T2m: 0.8468635778030965, T850: 0.8467625693884427, U10: 0.3787509969898105
2023-12-29 09:24:51,257 - forecast.py[line:256] - INFO: ================================End Evaluation================================
......
epoch: 91 step: 67, loss is 0.13158562
Train epoch time: 191498.866 ms, per step time: 2858.192 ms
epoch: 92 step: 67, loss is 0.12776905
Train epoch time: 218376.797 ms, per step time: 3259.355 ms
epoch: 93 step: 67, loss is 0.12682373
Train epoch time: 217263.432 ms, per step time: 3242.738 ms
epoch: 94 step: 67, loss is 0.12594032
Train epoch time: 217970.325 ms, per step time: 3253.288 ms
epoch: 95 step: 67, loss is 0.12149178
Train epoch time: 217401.066 ms, per step time: 3244.792 ms
epoch: 96 step: 67, loss is 0.12223453
Train epoch time: 218616.899 ms, per step time: 3265.344 ms
epoch: 97 step: 67, loss is 0.12046164
Train epoch time: 218616.899 ms, per step time: 3263.949 ms
epoch: 98 step: 67, loss is 0.1172382
Train epoch time: 216666.521 ms, per step time: 3233.829 ms
epoch: 99 step: 67, loss is 0.11799482
Train epoch time: 218090.233 ms, per step time: 3255.078 ms
epoch: 100 step: 67, loss is 0.11112012
Train epoch time: 218108.888 ms, per step time: 3255.357 ms
2023-12-29 10:00:44,043 - forecast.py[line:223] - INFO: ================================Start Evaluation================================
2023-12-29 10:02:59,291 - forecast.py[line:241] - INFO: test dataset size: 1
2023-12-29 10:02:59,293 - forecast.py[line:191] - INFO: t = 6 hour:
2023-12-29 10:02:59,294 - forecast.py[line:202] - INFO: RMSE of Z500: 159.26790471459077, T2m: 1.7593914514223792, T850: 1.2225771108909576, U10: 1.3952338408157166
2023-12-29 10:02:59,295 - forecast.py[line:203] - INFO: ACC of Z500: 0.996888905697735, T2m: 0.9882202464019967, T850: 0.994542681351491, U10: 0.9697411543132562
2023-12-29 10:02:59,297 - forecast.py[line:191] - INFO: t = 72 hour:
2023-12-29 10:02:59,298 - forecast.py[line:202] - INFO: RMSE of Z500: 937.2960233810791, T2m: 5.177728653933931, T850: 4.831667457069809, U10: 5.30111109022694
2023-12-29 10:02:59,299 - forecast.py[line:203] - INFO: ACC of Z500: 0.9542952919181137, T2m: 0.9557775651851869, T850: 0.9371537322317006, U10: 0.5895038993694246
2023-12-29 10:02:59,300 - forecast.py[line:191] - INFO: t = 120 hour:
2023-12-29 10:02:59,301 - forecast.py[line:202] - INFO: RMSE of Z500: 1200.9140481697198, T2m: 6.913749261896835, T850: 6.530332262562704, U10: 6.3855645042672835
2023-12-29 10:02:59,303 - forecast.py[line:203] - INFO: ACC of Z500: 0.9257611031529911, T2m: 0.9197160039098073, T850: 0.8867113860499101, U10: 0.47483364671406136
2023-12-29 10:02:59,304 - forecast.py[line:256] - INFO: ================================End Evaluation================================
模型评估和可视化
完成训练后,我们使用第100个ckpt进行推理。下述展示了预测值、地表和它们之间的误差可视化。
[7]:
params = load_checkpoint('./FuXi_depths_18_in_channels_96_out_channels_192_recompute_True_adam_oop/ckpt/step_1/FuXi-100_67.ckpt')
load_param_into_net(fuxi_model, params)
inference_module = InferenceModule(fuxi_model, config, logger_obj)
[8]:
data_params = config.get("data")
test_dataset_generator = Era5Data(data_params=data_params, run_mode='test')
test_dataset = Dataset(test_dataset_generator, distribute=False,
num_workers=data_params.get('num_workers'), shuffle=False)
test_dataset = test_dataset.create_dataset(data_params.get('batch_size'))
data = next(test_dataset.create_dict_iterator())
inputs = data['inputs']
labels = data['labels']
[9]:
labels = labels[..., 0, :, :]
labels = labels.transpose(0, 2, 1)
labels = labels.reshape(labels.shape[0], labels.shape[1], data_params.get("h_size"), data_params.get("w_size")).asnumpy()
pred = inference_module.forecast(inputs)
pred = pred[0].transpose(1, 0)
pred = pred.reshape(pred.shape[0], data_params.get("h_size"), data_params.get("w_size")).asnumpy()
pred = np.expand_dims(pred, axis=0)
[11]:
def plt_key_info_comparison(pred, label, root_dir):
""" Visualize the comparison of forecast results """
std = np.load(os.path.join(root_dir, 'statistic/std.npy'))
mean = np.load(os.path.join(root_dir, 'statistic/mean.npy'))
std_s = np.load(os.path.join(root_dir, 'statistic/std_s.npy'))
mean_s = np.load(os.path.join(root_dir, 'statistic/mean_s.npy'))
plt.figure(num='e_imshow', figsize=(100, 50))
plt.subplot(4, 3, 1)
plt_global_field_data(label, 'Z500', std, mean, 'Ground Truth') # Z500
plt.subplot(4, 3, 2)
plt_global_field_data(pred, 'Z500', std, mean, 'Pred') # Z500
plt.subplot(4, 3, 3)
plt_global_field_data(label - pred, 'Z500', std, mean, 'Error', is_error=True) # Z500
plt.subplot(4, 3, 4)
plt_global_field_data(label, 'T850', std, mean, 'Ground Truth') # T850
plt.subplot(4, 3, 5)
plt_global_field_data(pred, 'T850', std, mean, 'Pred') # T850
plt.subplot(4, 3, 6)
plt_global_field_data(label - pred, 'T850', std, mean, 'Error', is_error=True) # T850
plt.subplot(4, 3, 7)
plt_global_field_data(label, 'U10', std_s, mean_s, 'Ground Truth', is_surface=True) # U10
plt.subplot(4, 3, 8)
plt_global_field_data(pred, 'U10', std_s, mean_s, 'Pred', is_surface=True) # U10
plt.subplot(4, 3, 9)
plt_global_field_data(label - pred, 'U10', std_s, mean_s, 'Error', is_surface=True, is_error=True) # U10
plt.subplot(4, 3, 10)
plt_global_field_data(label, 'T2M', std_s, mean_s, 'Ground Truth', is_surface=True) # T2M
plt.subplot(4, 3, 11)
plt_global_field_data(pred, 'T2M', std_s, mean_s, 'Pred', is_surface=True) # T2M
plt.subplot(4, 3, 12)
plt_global_field_data(label - pred, 'T2M', std_s, mean_s, 'Error', is_surface=True, is_error=True) # T2M
plt.savefig(f'key_info_comparison1.png', bbox_inches='tight')
plt.show()
[1]:
plt_key_info_comparison(pred, labels, data_params.get('root_dir'))
