ViT-KNO: Medium-range Global Weather Forecasting Based on Koopman
![]()
![]()
![]()
Overview
Modern data weather prediction (Numerical Weather Prediction, NWP) can be traced back to 1920. Based on physical principles and integrating the achievements and experiences of several generations of meteorologists, NWP is the mainstream weather forecast method adopted by meteorological departments in various countries. Among them, the high resolution integrated system (IFS) model from the European Centre for Medium-Range Weather Forecasts (ECMWF) is the best.
Until 2022, Nvidia has developed a Fourier neural network-based prediction model, FourCastNet, which can generate predictions of key global weather indicators at a resolution of 0.25°. This corresponds to a spatial resolution of about 30×30 km near the equator and a weighted grid size of 720×1440 pixels, consistent with the IFS system. This result allows for the first direct comparison of AI weather models with the traditional physical model IFS. For more information, please refer to: “FourCastNet: A Global Data-driven High-resolution Weather Model using Adaptive Fourier Neural Operators”.
However, FourCastnet, a prediction model based on Fourier Neural Operator (FNO), is not accurate and interpretable in predicting medium-term and long-term weather. ViT-KNO makes full use of Vision Transformer structure and Koopman theory to learn Koopman Operator to predict nonlinear dynamic systems. By embedding complex dynamics into linear structures to constrain the reconstruction process, ViT-KNO can capture complex nonlinear behaviors while maintaining model lightweight and computational efficiency. ViT-KNO has clear mathematical theory support, and overcomes the problems of mathematical and physical explainability and lack of theoretical basis of similar methods. For more information, refer to: “KoopmanLab: machine learning for solving complex physics equations”.
Technology Path
MindSpore solves the problem as follows:
Training Data Construction.
Model Construction.
Loss function.
Model Training.
Model Evaluation and Visualization.
ViT-KNO
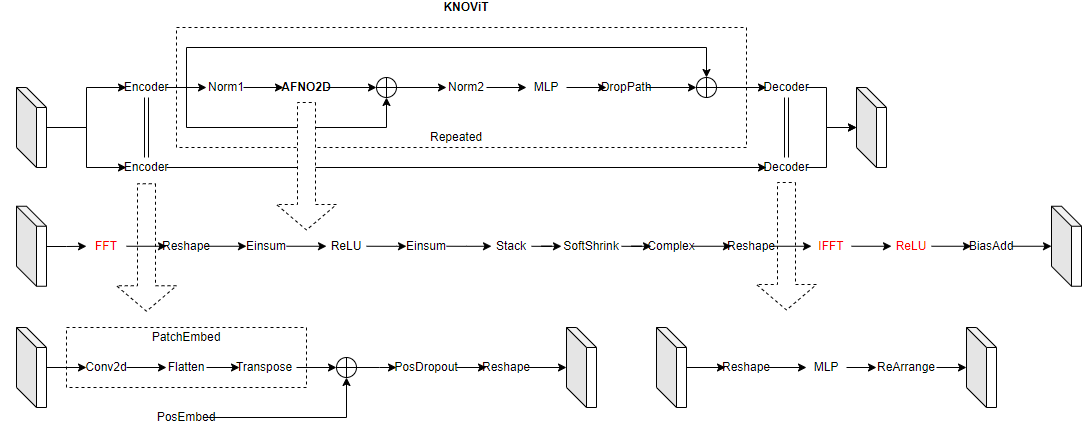
The following figure shows the ViT-KNO model architecture, which consists of two branches. The upstream branch is responsible for result prediction and consists of the encoder module, Koopman Layer module, and decoder module. The Koopman Layer module is shown in the dotted box and can be stacked repeatedly. The downstream branch consists of the encoder and decoder modules, which reconstruct input information.
The model training process is as follows:
[1]:
import os
import numpy as np
import matplotlib.pyplot as plt
from mindspore import context, Model
from mindspore import dtype as mstype
from mindspore.train.serialization import load_checkpoint, load_param_into_net
from mindspore.train.loss_scale_manager import DynamicLossScaleManager
from mindearth.cell import ViTKNO
from mindearth.utils import load_yaml_config, create_logger, plt_global_field_data
from mindearth.data import Dataset, Era5Data
from mindearth.module import Trainer
The following src can be downloaded in ViT-KNO/src.
[2]:
from src.callback import EvaluateCallBack, InferenceModule, Lploss, CustomWithLossCell
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", device_id=1)
You can get parameters of model, data and optimizer from vit_kno.yaml.
[3]:
config = load_yaml_config('./vit_kno.yaml')
config['model']['data_sink'] = True # set the data sink feature
config['train']['distribute'] = False # set the distribute feature
config['train']['amp_level'] = 'O2' # set the level for mixed precision training
config['data']['num_workers'] = 1 # set the number of parallel workers
config['data']['grid_resolution'] = 1.4 # set the resolution for dataset
config['optimizer']['epochs'] = 100 # set the training epochs
config['optimizer']['finetune_epochs'] = 1 # set the the finetune epochs
config['optimizer']['warmup_epochs'] = 1 # set the warmup epochs
config['optimizer']['initial_lr'] = 0.0001 # set the initial learning rate
config['summary']["valid_frequency"] = 10 # set the frequency of validation
config['summary']["summary_dir"] = './summary' # set the directory of model's checkpoint
logger = create_logger(path=os.path.join(config['summary']["summary_dir"], "results.log"))
Training Data Construction
Download the statistic, training and validation dataset from dataset to ./dataset.
Modify the parameter of root_dir in the vit_kno.yaml, which set the directory for dataset.
The ./dataset is hosted with the following directory structure:
.
├── statistic
│ ├── mean.npy
│ ├── mean_s.npy
│ ├── std.npy
│ └── std_s.npy
├── train
│ └── 2015
├── train_static
│ └── 2015
├── train_surface
│ └── 2015
├── train_surface_static
│ └── 2015
├── valid
│ └── 2016
├── valid_static
│ └── 2016
├── valid_surface
│ └── 2016
├── valid_surface_static
│ └── 2016
Model Construction
Load the data parameters and model parameters to the ViTKNO model.
[4]:
data_params = config["data"]
model_params = config["model"]
compute_type = mstype.float32
model = ViTKNO(image_size=(data_params["h_size"], data_params["w_size"]),
in_channels=data_params["feature_dims"],
out_channels=data_params["feature_dims"],
patch_size=data_params["patch_size"],
encoder_depths=model_params["encoder_depth"],
encoder_embed_dims=model_params["encoder_embed_dim"],
mlp_ratio=model_params["mlp_ratio"],
dropout_rate=model_params["dropout_rate"],
num_blocks=model_params["num_blocks"],
high_freq=True,
encoder_network=model_params["encoder_network"],
compute_dtype=compute_type)
Loss Function
ViT-KNO uses multi-loss training methods, including Prediction loss and Reconstruction loss, both based on mean squared error.
[5]:
loss_fn = Lploss()
loss_net = CustomWithLossCell(model, loss_fn)
Model Training
In this tutorial, we inherite the Trainer and override the get_dataset, get_callback and get_solver member functions so that we can perform inference on the test dataset during the training process.
[6]:
class ViTKNOEra5Data(Era5Data):
def _patch(self, x, img_size, patch_size, output_dims):
""" Partition the data into patches. """
if self.run_mode == 'valid' or self.run_mode == 'test':
x = x.transpose(1, 0, 2, 3)
return x
class ViTKNOTrainer(Trainer):
def __init__(self, config, model, loss_fn, logger):
super(ViTKNOTrainer, self).__init__(config, model, loss_fn, logger)
self.pred_cb = self.get_callback()
def get_dataset(self):
"""
Get train and valid dataset.
Returns:
Dataset, train dataset.
Dataset, valid dataset.
"""
train_dataset_generator = ViTKNOEra5Data(data_params=self.data_params, run_mode='train')
valid_dataset_generator = ViTKNOEra5Data(data_params=self.data_params, run_mode='valid')
train_dataset = Dataset(train_dataset_generator, distribute=self.train_params['distribute'],
num_workers=self.data_params['num_workers'])
valid_dataset = Dataset(valid_dataset_generator, distribute=False, num_workers=self.data_params['num_workers'],
shuffle=False)
train_dataset = train_dataset.create_dataset(self.data_params['batch_size'])
valid_dataset = valid_dataset.create_dataset(self.data_params['batch_size'])
return train_dataset, valid_dataset
def get_callback(self):
pred_cb = EvaluateCallBack(self.model, self.valid_dataset, self.config, self.logger)
return pred_cb
def get_solver(self):
loss_scale = DynamicLossScaleManager()
solver = Model(self.loss_fn,
optimizer=self.optimizer,
loss_scale_manager=loss_scale,
amp_level=self.train_params['amp_level']
)
return solver
trainer = ViTKNOTrainer(config, model, loss_net, logger)
2023-09-07 02:22:28,644 - pretrain.py[line:211] - INFO: steps_per_epoch: 404
[7]:
trainer.train()
epoch: 1 step: 404, loss is 0.3572
Train epoch time: 113870.065 ms, per step time: 281.857 ms
epoch: 2 step: 404, loss is 0.2883
Train epoch time: 38169.970 ms, per step time: 94.480 ms
epoch: 3 step: 404, loss is 0.2776
Train epoch time: 38192.446 ms, per step time: 94.536 ms
...
epoch: 98 step: 404, loss is 0.1279
Train epoch time: 38254.867 ms, per step time: 94.690 ms
epoch: 99 step: 404, loss is 0.1306
Train epoch time: 38264.715 ms, per step time: 94.715 ms
epoch: 100 step: 404, loss is 0.1301
Train epoch time: 41886.174 ms, per step time: 103.679 ms
2023-09-07 03:38:51,759 - forecast.py[line:209] - INFO: ================================Start Evaluation================================
2023-09-07 03:39:57,551 - forecast.py[line:227] - INFO: test dataset size: 9
2023-09-07 03:39:57,555 - forecast.py[line:177] - INFO: t = 6 hour:
2023-09-07 03:39:57,555 - forecast.py[line:188] - INFO: RMSE of Z500: 199.04419938873764, T2m: 2.44011585143782, T850: 1.45654734158296, U10: 1.636622237572019
2023-09-07 03:39:57,556 - forecast.py[line:189] - INFO: ACC of Z500: 0.9898813962936401, T2m: 0.9677559733390808, T850: 0.9703396558761597, U10: 0.9609741568565369
2023-09-07 03:39:57,557 - forecast.py[line:177] - INFO: t = 72 hour:
2023-09-07 03:39:57,557 - forecast.py[line:188] - INFO: RMSE of Z500: 925.158453845783, T2m: 4.638264378699863, T850: 4.385266743972255, U10: 4.761954010777025
2023-09-07 03:39:57,558 - forecast.py[line:189] - INFO: ACC of Z500: 0.7650538682937622, T2m: 0.8762193918228149, T850: 0.7014696598052979, U10: 0.6434637904167175
2023-09-07 03:39:57,559 - forecast.py[line:177] - INFO: t = 120 hour:
2023-09-07 03:39:57,559 - forecast.py[line:188] - INFO: RMSE of Z500: 1105.3634480837272, T2m: 5.488261092294651, T850: 5.120214326468169, U10: 5.424460568523809
2023-09-07 03:39:57,560 - forecast.py[line:189] - INFO: ACC of Z500: 0.6540136337280273, T2m: 0.8196010589599609, T850: 0.5682352781295776, U10: 0.5316879749298096
2023-09-07 03:39:57,561 - forecast.py[line:237] - INFO: ================================End Evaluation================================
Model Evaluation and Visualization
After training, we use the 100th checkpoint for inference.
[8]:
params = load_checkpoint('./summary/ckpt/step_1/koopman_vit_2-100_404.ckpt')
load_param_into_net(model, params)
inference_module = InferenceModule(model, config, logger)
[9]:
def plt_data(pred, label, root_dir, index=0):
""" Visualize the forecast results """
std = np.load(os.path.join(root_dir, 'statistic/std.npy'))
mean = np.load(os.path.join(root_dir, 'statistic/mean.npy'))
std_s = np.load(os.path.join(root_dir, 'statistic/std_s.npy'))
mean_s = np.load(os.path.join(root_dir, 'statistic/mean_s.npy'))
plt.figure(num='e_imshow', figsize=(100, 50), dpi=50)
plt.subplot(4, 3, 1)
plt_global_field_data(label, 'Z500', std, mean, 'Ground Truth') # Z500
plt.subplot(4, 3, 2)
plt_global_field_data(pred, 'Z500', std, mean, 'Pred') # Z500
plt.subplot(4, 3, 3)
plt_global_field_data(label - pred, 'Z500', std, mean, 'Error') # Z500
plt.subplot(4, 3, 4)
plt_global_field_data(label, 'T850', std, mean, 'Ground Truth') # T850
plt.subplot(4, 3, 5)
plt_global_field_data(pred, 'T850', std, mean, 'Pred') # T850
plt.subplot(4, 3, 6)
plt_global_field_data(label - pred, 'T850', std, mean, 'Error') # T850
plt.subplot(4, 3, 7)
plt_global_field_data(label, 'U10', std_s, mean_s, 'Ground Truth', is_surface=True) # U10
plt.subplot(4, 3, 8)
plt_global_field_data(pred, 'U10', std_s, mean_s, 'Pred', is_surface=True) # U10
plt.subplot(4, 3, 9)
plt_global_field_data(label - pred, 'U10', std_s, mean_s, 'Error', is_surface=True) # U10
plt.subplot(4, 3, 10)
plt_global_field_data(label, 'T2M', std_s, mean_s, 'Ground Truth', is_surface=True) # T2M
plt.subplot(4, 3, 11)
plt_global_field_data(pred, 'T2M', std_s, mean_s, 'Pred', is_surface=True) # T2M
plt.subplot(4, 3, 12)
plt_global_field_data(label - pred, 'T2M', std_s, mean_s, 'Error', is_surface=True) # T2M
plt.savefig(f'pred_result.png', bbox_inches='tight')
plt.show()
[10]:
test_dataset_generator = Era5Data(data_params=config["data"], run_mode='test')
test_dataset = Dataset(test_dataset_generator, distribute=False,
num_workers=config["data"]['num_workers'], shuffle=False)
test_dataset = test_dataset.create_dataset(config["data"]['batch_size'])
data = next(test_dataset.create_dict_iterator())
inputs = data['inputs']
labels = data['labels']
pred_time_index = 0
pred = inference_module.forecast(inputs)
pred = pred[pred_time_index].asnumpy()
ground_truth = labels[..., pred_time_index, :, :].asnumpy()
plt_data(pred, ground_truth, config['data']['root_dir'])
The visualization of predictions by the 100th checkpoint, ground truth and their error is shown below.
