使用Python接口执行云侧推理
![]()
概述
本教程提供了MindSpore Lite执行云侧推理的示例程序,通过文件输入、执行推理、打印推理结果的方式,演示了Python接口进行云侧推理的基本流程,用户能够快速了解MindSpore Lite执行云侧推理相关API的使用。相关代码放置在mindspore/lite/examples/cloud_infer/quick_start_python目录。
MindSpore Lite云侧推理仅支持在Linux环境部署运行。支持Atlas 200/300/500推理产品、Atlas推理系列产品(配置Ascend310P AI 处理器)、Atlas训练系列产品、Nvidia GPU和CPU硬件后端。
下面以Ubuntu 18.04为例,介绍了在Linux X86操作系统配合CPU硬件平台下如何使用Python云侧推理Demo:
一键安装
本环节以全新的Ubuntu 18.04为例,介绍在CPU环境的Linux-x86_64系统上,通过pip安装Python3.7版本的MindSpore Lite。
进入到mindspore/lite/examples/cloud_infer/quick_start_python目录下,以安装2.0.0版本的MindSpore Lite为例,执行lite-cpu-pip.sh脚本进行一键式安装。安装脚本会下载推理所需的模型和输入数据文件、安装MindSpore_Lite所需的依赖,以及下载并安装MindSpore Lite。
注:此命令可设置安装的MindSpore Lite版本,由于从MindSpore Lite 2.0.0版本开始支持云侧推理的Python接口,因此版本不能设置低于2.0.0,可设置的版本详情参见下载MindSpore Lite提供的版本。
MINDSPORE_LITE_VERSION=2.0.0 bash ./lite-cpu-pip.sh
若MobileNetV2模型下载失败,请手动下载相关模型文件mobilenetv2.mindir,并将其拷贝到
mindspore/lite/examples/cloud_infer/quick_start_python/model目录。若input.bin输入数据文件下载失败,请手动下载相关输入数据文件input.bin,并将其拷贝到
mindspore/lite/examples/cloud_infer/quick_start_python/model目录。若使用脚本下载MindSpore Lite推理框架失败,请手动下载对应硬件平台为CPU、操作系统为Linux-x86_64或Linux-aarch64的MindSpore Lite 模型云侧推理框架,用户可以使用
uname -m命令在终端上查询操作系统,并将其拷贝到mindspore/lite/examples/cloud_infer/quick_start_python目录下。若需要使用Python3.7以上版本对应的MindSpore Lite,请在本地编译,注意Python API模块编译依赖:Python >= 3.7.0、NumPy >= 1.17.0、wheel >= 0.32.0。编译成功后,将
output/目录下生成的Whl安装包拷贝到mindspore/lite/examples/cloud_infer/quick_start_python目录下。若
mindspore/lite/examples/cloud_infer/quick_start_python目录下不存在MindSpore Lite安装包,则一键安装脚本将会卸载当前已安装的MindSpore Lite后,从华为镜像下载并安装MindSpore Lite。否则,若目录下存在MindSpore Lite安装包,则会优先安装该安装包。通过手动下载并且将文件放到指定位置后,需要再次执行lite-cpu-pip.sh脚本才能完成一键安装。
执行成功将会显示如下结果,模型文件和输入数据文件可在mindspore/lite/examples/cloud_infer/quick_start_python/model目录下找到。
Successfully installed mindspore-lite-2.0.0
执行Demo
一键安装后,进入mindspore/lite/examples/cloud_infer/quick_start_python目录,并执行以下命令,体验MindSpore Lite推理MobileNetV2模型。
python quick_start_cloud_infer_python.py
执行完成后将能得到如下结果,打印输出Tensor的名称、输出Tensor的数据大小,输出Tensor的元素数量以及前50个数据。
tensor's name is:shape1 data size is:4000 tensor elements num is:1000
output data is: 5.3937547e-05 0.00037763786 0.00034193686 0.00037316754 0.00022436169 9.953917e-05 0.00025308868 0.00032044895 0.00025788433 0.00018915901 0.00079509866 0.003382262 0.0016214572 0.0010760546 0.0023826156 0.0011769629 0.00088481285 0.000534926 0.0006929171 0.0010826243 0.0005747609 0.0014443205 0.0010454883 0.0016276307 0.00034437355 0.0001039985 0.00022641376 0.00035307938 0.00014567627 0.00051178376 0.00016933997 0.00075814105 9.704676e-05 0.00066705025 0.00087511574 0.00034623547 0.00026317223 0.000319407 0.0015627446 0.0004044049 0.0008798965 0.0005202293 0.00044808138 0.0006453716 0.00044969268 0.0003431648 0.0009871059 0.00020436312 7.405098e-05 8.805057e-05
Demo内容说明
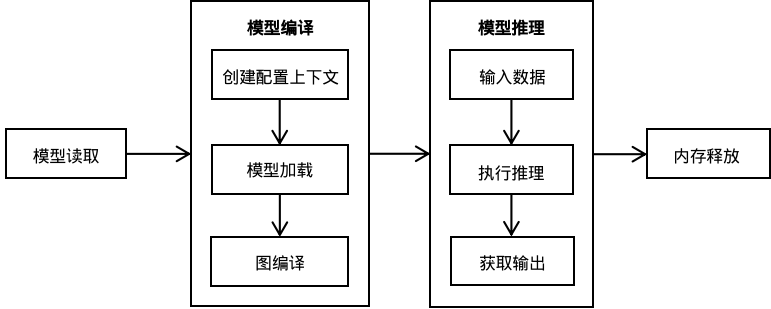
使用MindSpore Lite推理框架主要包括以下步骤:
模型读取:通过MindSpore导出MindIR模型,或者由模型转换工具转换获得MindIR模型。
创建配置上下文:创建配置上下文Context,保存需要的一些基本配置参数,用于指导模型编译和模型执行。
模型加载与编译:执行推理之前,需要调用Model的build_from_file接口进行模型加载和模型编译。模型加载阶段将文件缓存解析成运行时的模型。模型编译阶段会耗费较多时间所以建议Model创建一次,编译一次,多次推理。
输入数据:模型执行之前需要填充输入数据。
更多Python接口的高级用法与示例,请参考Python API。
创建配置上下文
创建配置上下文Context。由于本教程演示的是在CPU设备上执行推理的场景,因此需要设置上下文的目标设备为cpu。
import numpy as np
import mindspore_lite as mslite
# init context, and set target is cpu
context = mslite.Context()
context.target = ["cpu"]
context.cpu.thread_num = 1
context.cpu.thread_affinity_mode=2
如果用户需要在Ascend设备上运行推理时,因此需要设置上下文的目标设备为ascend。
import numpy as np
import mindspore_lite as mslite
# init context, and set target is ascend.
context = mslite.Context()
context.target = ["ascend"]
context.ascend.device_id = 0
context.cpu.thread_num = 1
context.cpu.thread_affinity_mode=2
如果需要在Ascend弹性加速服务环境(拉远模式)推理,需要配置provider为ge。
context.ascend.provider = "ge"
如果用户需要在GPU设备上运行推理时,因此需要设置上下文的目标设备为gpu。
import numpy as np
import mindspore_lite as mslite
# init context, and set target is gpu.
context = mslite.Context()
context.target = ["gpu"]
context.gpu.device_id = 0
context.cpu.thread_num = 1
context.cpu.thread_affinity_mode=2
模型加载与编译
模型加载与编译可以调用Model的build_from_file接口,直接从文件缓存加载、编译得到运行时的模型。
# build model from file
MODEL_PATH = "./model/mobilenetv2.mindir"
IN_DATA_PATH = "./model/input.bin"
model = mslite.Model()
model.build_from_file(MODEL_PATH, mslite.ModelType.MINDIR, context)
输入数据
本教程设置输入数据的方式是从文件导入。其他设置输入数据的方式,请参考Model的predict接口。
# set model input
inputs = model.get_inputs()
in_data = np.fromfile(IN_DATA_PATH, dtype=np.float32)
inputs[0].set_data_from_numpy(in_data)
执行推理
调用Model的predict接口执行推理,推理结果输出给output。
# execute inference
outputs = model.predict(inputs)
获得输出
打印执行推理后的输出结果。遍历outputs列表,打印每个输出Tensor的名字、数据大小、元素数量、以及前50个数据。
# get output
for output in outputs:
name = output.name.rstrip()
data_size = output.data_size
element_num = output.element_num
print("tensor's name is:%s data size is:%s tensor elements num is:%s" % (name, data_size, element_num))
data = output.get_data_to_numpy()
data = data.flatten()
print("output data is:", end=" ")
for i in range(50):
print(data[i], end=" ")
print("")
动态权重更新
MindSpore Lite推理,在Ascend后端上支持动态权重更新,使用步骤如下所示:
创建配置文件
将需要更新的Matmul算子所对应的Tensor名称全部写入一个文本文件中,每个Tensor名字占一行。构建模型加载配置文件,配置文件设置,配置文件config.ini内容如下所示:
[ascend_context]
variable_weights_file="update_weight_name_list.txt"
模型加载
import numpy as np
import mindspore_lite as mslite
# init context, and set target is gpu.
context = mslite.Context()
context.target = ["ascend"]
context.gpu.device_id = 0
# build model from file
MODEL_PATH = "./SD1.5/unet.mindir"
model = mslite.Model()
model.build_from_file(MODEL_PATH, mslite.ModelType.MINDIR, context, "config.ini")
构建新权重tensor
将第三方框架训练导出的SaveTensor数据结构转换成MindSpore Lite能支持的Tensor格式。
更新权重
调用MindSpore Lite提供的update_weights接口更新权重,如下所示:
new_weight = mslite.Tensor(data)
new_weights = [new_weight]
model.update_weights([new_weights])