使用Java接口执行推理
![]()
概述
通过MindSpore Lite模型转换工具转换成.ms模型后,即可在Runtime中执行模型的推理流程。本教程介绍如何使用JAVA接口执行推理。
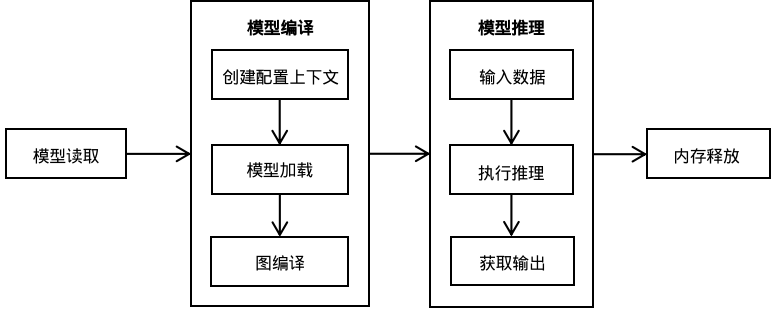
Android项目中使用MindSpore Lite,可以选择采用C++ API或者Java API运行推理框架。Java API与C++ API相比较而言,Java API可以直接在Java Class中调用,用户无需实现JNI层的相关代码,具有更好的便捷性。运行MindSpore Lite推理框架主要包括以下步骤:
模型读取(可选):从文件系统中读取由模型转换工具转换得到的
.ms模型。创建配置上下文:创建配置上下文MSContext,保存需要的一些基本配置参数,用于指导模型编译和模型执行,包括设备类型、线程数、绑核模式和使能fp16混合精度推理。
模型创建、加载与编译:执行推理之前,需要调用Model的build接口进行模型加载和模型编译,目前支持加载文件和MappedByteBuffer两种方式。模型加载阶段将文件或者buffer解析成运行时的模型。模型编译阶段主要进行算子选型调度、子图切分等过程,该阶段会耗费较多时间所以建议Model创建一次,编译一次,多次推理。
输入数据:模型执行之前需要向
输入Tensor中填充数据。获得输出:图执行结束之后,可以通过
输出Tensor得到推理结果。释放内存:无需使用MindSpore Lite推理框架的时候,需要释放已创建的Model
快速了解MindSpore Lite执行推理的完整调用流程,请参考体验Java极简推理Demo。
引用MindSpore Lite Java库
Linux X86项目引用JAR库
采用Maven作为构建工具时,可将mindspore-lite-java.jar拷贝到根目录下的lib目录,并在pom.xml中增加jar包的依赖。
<dependencies>
<dependency>
<groupId>com.mindspore.lite</groupId>
<artifactId>mindspore-lite-java</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/mindspore-lite-java.jar</systemPath>
</dependency>
</dependencies>
运行时需要将
libmindspore-lite.so以及libminspore-lite-jni.so的所在路径添加到java.library.path。
Android项目引用AAR库
采用Gradle作为构建工具时,首先将mindspore-lite-{version}.aar文件移动到目标module的libs目录,然后在目标module的build.gradle的repositories中添加本地引用目录,最后在dependencies中添加AAR的依赖,具体如下所示。
注意mindspore-lite-{version}是AAR的文件名,需要将{version}替换成对应版本信息。
repositories {
flatDir {
dirs 'libs'
}
}
dependencies {
implementation fileTree(dir: "libs", include: ['*.aar'])
}
模型读取
MindSpore Lite进行模型推理时,需要先从文件系统中加载模型转换工具转换后的.ms模型,并进行模型解析。
下面[示例代码]从指定的文件路径读取模型文件。
// Load the .ms model.
MappedByteBuffer byteBuffer = null;
try {
fc = new RandomAccessFile(fileName, "r").getChannel();
byteBuffer = fc.map(FileChannel.MapMode.READ_ONLY, 0, fc.size()).load();
} catch (IOException e) {
e.printStackTrace();
}
创建配置上下文
创建配置上下文MSContext,保存会话所需的一些基本配置参数,用于指导图编译和图执行。通过init接口配置线程数,线程亲和性和是否开启异构并行推理。MindSpore Lite内置一个进程共享的线程池,推理时通过threadNum指定线程池的最大线程数,默认为2线程。
MindSpore Lite推理时的后端可调用AddDeviceInfo接口中的deviceType指定,目前支持CPU、GPU和NPU。在进行图编译时,会根据主选后端进行算子选型调度。如果后端支持Float16,可通过设置isEnableFloat16为true后,优先使用Float16算子。如果是NPU后端,还可以设置NPU频率值。频率值默认为3,可设置为1(低功耗)、2(均衡)、3(高性能)、4(极致性能)。
配置使用CPU后端
当需要执行的后端为CPU时,MSContext初始化后需要在addDeviceInfo中DeviceType.DT_CPU,同时CPU支持设置绑核模式以及是否优先使用Float16算子。
下面示例代码演示如何创建CPU后端,同时设定线程数为2、CPU绑核模式为大核优先并且使能Float16推理,关闭并行:
MSContext context = new MSContext();
context.init(2, CpuBindMode.HIGHER_CPU);
context.addDeviceInfo(DeviceType.DT_CPU, true);
Float16需要CPU为ARM v8.2架构的机型才能生效,其他不支持的机型和x86平台会自动回退到Float32执行。
配置使用GPU后端
当需要执行的后端为CPU和GPU的异构推理时,MSContext创建后需要在addDeviceInfo中先后添加GPUDeviceInfo和CPUDeviceInfo,配置后将会优先使用GPU推理。如果使能Float16推理,GPU和CPU都会优先使用Float16算子。
下面代码演示了如何创建CPU与GPU异构推理后端,同时GPU也设定使能Float16推理:
MSContext context = new MSContext();
context.init(2, CpuBindMode.MID_CPU);
context.addDeviceInfo(DeviceType.DT_GPU, true);
context.addDeviceInfo(DeviceType.DT_CPU, true);
目前GPU只能在Android手机端侧运行,所以只有
AAR库才能支持运行。
配置使用NPU后端
当需要执行的后端为CPU和GPU的异构推理时,MSContext创建后需要在addDeviceInfo中先后添加KirinNPUDeviceInfo和CPUDeviceInfo,配置后将会优先使用NPU推理。如果使能Float16推理,NPU和CPU都会优先使用Float16算子。
下面代码演示了如何创建CPU与GPU异构推理后端,其中KirinNPUDeviceInfo可通过NPUFrequency来设置NPU频率。
MSContext context = new MSContext();
context.init(2, CpuBindMode.MID_CPU);
context.addDeviceInfo(DeviceType.DT_NPU, true, 3);
context.addDeviceInfo(DeviceType.DT_CPU, true);
模型创建加载与编译
使用MindSpore Lite执行推理时,Model是推理的主入口,通过Model可以实现模型加载、模型编译和模型执行。采用上一步创建得到的MSContext,调用Model的复合build接口来实现模型加载与模型编译。
下面[示例代码]演示了Model创建、加载与编译的过程:
Model model = new Model();
boolean ret = model.build(filePath, ModelType.MT_MINDIR, msContext);
输入数据
MindSpore Lite Java接口提供getInputsByTensorName以及getInputs两种方法获得输入Tensor,同时支持byte[]或者ByteBuffer两种类型的数据,通过setData设置输入Tensor的数据。
使用getInputsByTensorName方法,根据模型输入Tensor的名称来获取模型输入Tensor中连接到输入节点的Tensor,下面示例代码演示如何调用
getInputsByTensorName获得输入Tensor并填充数据。MSTensor inputTensor = model.getInputsByTensorName("2031_2030_1_construct_wrapper:x"); // Set Input Data. inputTensor.setData(inputData);
使用getInputs方法,直接获取所有的模型输入Tensor的vector,下面示例代码演示如何调用
getInputs获得输入Tensor并填充数据。List<MSTensor> inputs = model.getInputs(); MSTensor inputTensor = inputs.get(0); // Set Input Data. inputTensor.setData(inputData);
执行推理
MindSpore Lite在模型编译以后,即可调用Model的predict执行模型推理。
下面示例代码演示调用``执行推理。
// Run graph to infer results.
boolean ret = model.predict();
获得输出
MindSpore Lite在执行完推理后,可以通过输出Tensor得到推理结果。MindSpore Lite提供三种方法来获取模型的输出MSTensor,同时支持getByteData、getFloatData、getIntData、getLongData四种方法获得输出数据。
使用getOutputs方法,直接获取所有的模型输出MSTensor的列表。下面示例代码演示如何调用
getOutputs获得输出Tensor列表。List<MSTensor> outTensors = model.getOutputs();
使用getOutputsByNodeName方法,根据模型输出节点的名称来获取模型输出MSTensor中连接到该节点的Tensor的vector。下面示例代码演示如何调用
getOutputByTensorName获得输出Tensor。MSTensor outTensor = model.getOutputsByNodeName("Default/head-MobileNetV2Head/Softmax-op204"); // Apply infer results. ...
使用getOutputByTensorName方法,根据模型输出Tensor的名称来获取对应的模型输出MSTensor。下面示例代码演示如何调用
getOutputByTensorName获得输出Tensor。MSTensor outTensor = model.getOutputByTensorName("Default/head-MobileNetV2Head/Softmax-op204"); // Apply infer results. ...
释放内存
无需使用MindSpore Lite推理框架时,需要释放已经创建的Model,下列示例代码演示如何在程序结束前进行内存释放。
model.free();
高级用法
输入维度Resize
使用MindSpore Lite进行推理时,如果需要对输入的shape进行Resize,则可以在模型编译build之后调用Model的Resize接口,对输入的Tensor重新设置shape。
某些网络是不支持可变维度,会提示错误信息后异常退出,比如,模型中有MatMul算子,并且MatMul的一个输入Tensor是权重,另一个输入Tensor是输入时,调用可变维度接口会导致输入Tensor和权重Tensor的Shape不匹配,最终导致推理失败。
下面示例代码演示如何对MindSpore Lite的输入Tensor进行Resize:
List<MSTensor> inputs = model.getInputs();
int[][] dims = {{1, 300, 300, 3}};
bool ret = model.resize(inputs, dims);
Model并行
MindSpore Lite支持多个Model并行推理,每个Model的线程池和内存池都是独立的。但不支持多个线程同时调用单个Model的predict接口。
model1 = createLiteModel(modelPath, false);
if (model1 != null) {
model1Compile = true;
} else {
Toast.makeText(getApplicationContext(), "model1 Compile Failed.",
Toast.LENGTH_SHORT).show();
}
model2 = createLiteModel(modelPath, true);
if (model2 != null) {
model2Compile = true;
} else {
Toast.makeText(getApplicationContext(), "model2 Compile Failed.",
Toast.LENGTH_SHORT).show();
}
...
if (model1Finish && model1Compile) {
new Thread(new Runnable() {
@Override
public void run() {
model1Finish = false;
runInference(model2);
model1Finish = true;
}
}).start();
}
if (model2Finish && model2Compile) {
new Thread(new Runnable() {
@Override
public void run() {
model2Finish = false;
runInference(model2);
model2Finish = true;
}
}).start();
}
MindSpore Lite不支持多线程并行执行单个Model的推理,否则会得到以下错误信息:
ERROR [mindspore/lite/src/lite_session.cc:297] RunGraph] 10 Not support multi-threading
查看日志
当推理出现异常的时候,可以通过查看日志信息来定位问题。针对Android平台,采用Logcat命令行工具查看MindSpore Lite推理的日志信息,并利用MS_LITE 进行筛选。
logcat -s "MS_LITE"
获取版本号
MindSpore Lite提供了Version方法可以获取版本号,包含在com.mindspore.lite.config.Version头文件中,调用该方法可以得到当前MindSpore Lite的版本号。
下面示例代码演示如何获取MindSpore Lite的版本号:
import com.mindspore.lite.config.Version;
String version = Version.version();