Using Python Interface to Perform Cloud-side Inference
![]()
Overview
This tutorial provides a sample program for MindSpore Lite to perform cloud-side inference, demonstrating the Python interface to perform the basic process of cloud-side inference through file input, inference execution, and inference result printing, and enables users to quickly understand the use of MindSpore Lite APIs related to cloud-side inference execution. The related files are put in the directory mindspore/lite/examples/cloud_infer/quick_start_python.
MindSpore Lite cloud-side inference is supported to run in Linux environment deployment only. Ascend 310/310P/910, Nvidia GPU and CPU hardware backends are supported.
The following is an example of how to use the Python Cloud-side Inference Demo on a Linux X86 operating system and a CPU hardware platform, using Ubuntu 18.04 as an example:
One-click installation of inference-related model files, MindSpore Lite and its required dependencies. See the One-click installation section for details.
Execute the Python Cloud-side Inference Demo. See the Execute Demo section for details.
For a description of the Python Cloud-side Inference Demo content, see the Demo Content Description section for details.
One-click Installation
This session introduces the installation of MindSpore Lite for Python version 3.7 via pip on a Linux-x86_64 system with a CPU environment, taking the new Ubuntu 18.04 as an example.
Go to the mindspore/lite/examples/cloud_infer/quick_start_python directory, and execute the lite-cpu-pip.sh script for a one-click installation, taking installation of MindSpore Lite version 2.0.0 as an example. Script installation needs to download the model required for inference and input data files, the dependencies required for MindSpore_Lite installation, and download and install MindSpore Lite.
Note: This command sets the installed version of MindSpore Lite. Since the cloud-side inference Python interface is supported from MindSpore Lite version 2.0.0, the version cannot be set lower than 2.0.0. See the version provided in Download MindSpore Lite for details on the versions that can be set.
MINDSPORE_LITE_VERSION=2.0.0 bash ./lite-cpu-pip.sh
If the MobileNetV2 model download fails, please manually download the relevant model file mobilenetv2.mindir and copy it to the
mindspore/lite/examples/cloud_infer/quick_start_python/modeldirectory.If the input.bin input data file download fails, please manually download the relevant input data file input.bin and copy it to the
mindspore/lite/examples/cloud_infer/quick_start_python/modeldirectory.If MindSpore Lite inference framework by using the script download fails, please manually download MindSpore Lite model cloud-side inference framework corresponding to the hardware platform of CPU and operating system of Linux-x86_64 or Linux-aarch64. Users can use the
uname -mcommand to query the operating system in the terminal, and copy it to themindspore/lite/examples/cloud_infer/quick_start_pythondirectory.If you need to use MindSpore Lite corresponding to Python 3.7 or above, please compile locally. Note that the Python API module compilation depends on Python >= 3.7.0, NumPy >= 1.17.0, wheel >= 0.32.0. After successful compilation, copy the Whl installation package generated in the
output/directory to themindspore/lite/examples/cloud_infer/quick_start_pythondirectory.If the MindSpore Lite installation package does not exist in the
mindspore/lite/examples/cloud_infer/quick_start_pythondirectory, the one-click installation script will uninstall the currently installed MindSpore Lite and then download and install MindSpore Lite from the Huawei image. Otherwise, if the MindSpore Lite installation package exists in the directory, it will be installed first.After manually downloading and placing the files in the specified location, you need to execute the lite-cpu-pip.sh script again to complete the one-click installation.
A successful execution will show the following results. The model files and input data files can be found in the mindspore/lite/examples/cloud_infer/quick_start_python/model directory.
Successfully installed mindspore-lite-2.0.0
Executing Demo
After one-click installation, go to the mindspore/lite/examples/cloud_infer/quick_start_python directory and execute the following command to experience MindSpore Lite inference MobileNetV2 models.
python quick_start_cloud_infer_python.py
When the execution is completed, the following results will be obtained, printing the name of the output Tensor, the data size of the output Tensor, the number of elements of the output Tensor and the first 50 pieces of data.
tensor's name is:shape1 data size is:4000 tensor elements num is:1000
output data is: 5.3937547e-05 0.00037763786 0.00034193686 0.00037316754 0.00022436169 9.953917e-05 0.00025308868 0.00032044895 0.00025788433 0.00018915901 0.00079509866 0.003382262 0.0016214572 0.0010760546 0.0023826156 0.0011769629 0.00088481285 0.000534926 0.0006929171 0.0010826243 0.0005747609 0.0014443205 0.0010454883 0.0016276307 0.00034437355 0.0001039985 0.00022641376 0.00035307938 0.00014567627 0.00051178376 0.00016933997 0.00075814105 9.704676e-05 0.00066705025 0.00087511574 0.00034623547 0.00026317223 0.000319407 0.0015627446 0.0004044049 0.0008798965 0.0005202293 0.00044808138 0.0006453716 0.00044969268 0.0003431648 0.0009871059 0.00020436312 7.405098e-05 8.805057e-05
Demo Content Description
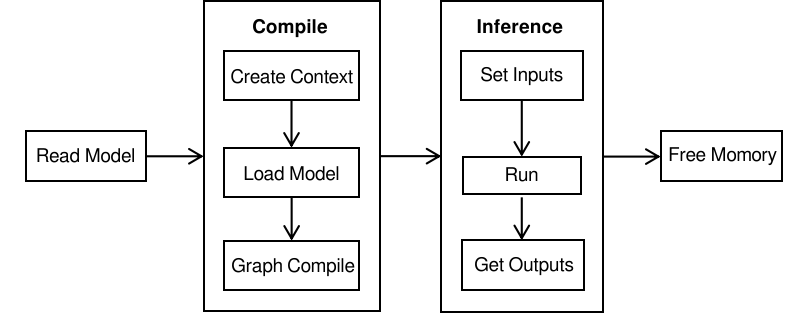
Running MindSpore Lite inference framework mainly consists of the following steps:
Model reading: Export MindIR model via MindSpore or get MindIR model by model conversion tool.
Create configuration context: Create a configuration context Context and save some basic configuration parameters used to guide model compilation and model execution.
Model creation and compilation: Before executing inference, you need to call build_from_file interface of Model for model loading and model compilation. The model loading phase parses the file cache into a runtime model. The model compilation phase can take more time, so it is recommended that the model be created once, compiled once and performed inference about multiple times.
Input data: The input data needs to be padded before the model execution.
Execute inference: Use Predict of Model method for model inference.
For more advanced usage and examples of Python interfaces, please refer to the Python API.
Creating Configuration Context
Create the configuration context Context. Since this tutorial demonstrates a scenario where inference is performed on a CPU device, they need to set Context’s target to cpu.
import numpy as np
import mindspore_lite as mslite
# init context, and set target is cpu
context = mslite.Context()
context.target = ["cpu"]
context.cpu.thread_num = 1
context.cpu.thread_affinity_mode=2
If the user needs to run inference on Ascend device, they need to set Context’s target to ascend.
import numpy as np
import mindspore_lite as mslite
# init context, and set target is ascend.
context = mslite.Context()
context.target = ["ascend"]
context.ascend.device_id = 0
context.cpu.thread_num = 1
context.cpu.thread_affinity_mode=2
If the backend is Ascend deployed on the Elastic Cloud Server, set the provider to ge.
context.ascend.provider = "ge"
If the user needs to run inference on a GPU device, they need to set Context’s target to gpu.
import numpy as np
import mindspore_lite as mslite
# init context, and set target is gpu.
context = mslite.Context()
context.target = ["gpu"]
context.gpu.device_id = 0
context.cpu.thread_num = 1
context.cpu.thread_affinity_mode=2
Model Loading and Compilation
Model loading and compilation can be done by calling build_from_file interface of Model to load and compile the runtime model directly from the file cache.
# build model from file
MODEL_PATH = "./model/mobilenetv2.mindir"
IN_DATA_PATH = "./model/input.bin"
model = mslite.Model()
model.build_from_file(MODEL_PATH, mslite.ModelType.MINDIR, context)
Inputting the Data
The way that this tutorial sets the input data is importing from a file. For other ways to set the input data, please refer to predict interface of Model.
# set model input
inputs = model.get_inputs()
in_data = np.fromfile(IN_DATA_PATH, dtype=np.float32)
inputs[0].set_data_from_numpy(in_data)
Executing Inference
Call predict interface of Model to perform inference, and the inference result is output to output.
# execute inference
outputs = model.predict(inputs)
Obtaining the Output
Print the output results after performing inference. Iterate through the outputs list and print the name, data size, number of elements, and the first 50 data for each output Tensor.
# get output
for output in outputs:
name = output.name.rstrip()
data_size = output.data_size
element_num = output.element_num
print("tensor's name is:%s data size is:%s tensor elements num is:%s" % (name, data_size, element_num))
data = output.get_data_to_numpy()
data = data.flatten()
print("output data is:", end=" ")
for i in range(50):
print(data[i], end=" ")
print("")