Using C++ Interface to Perform Cloud-side Inference
![]()
Overview
This tutorial describes how to perform cloud-side inference with MindSpore Lite by using the C++ interface.
MindSpore Lite cloud-side inference is supported to run in Linux environment deployment only. Ascend 310/310P/910, Nvidia GPU and CPU hardware backends are supported.
To experience the MindSpore Lite device-side inference process, please refer to the document Using C++ Interface to Perform Cloud-side Inference.
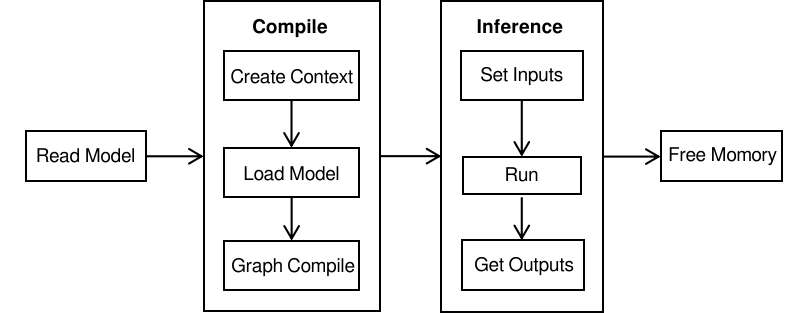
Using the MindSpore Lite inference framework consists of the following main steps:
Model reading: Export MindIR model via MindSpore or get MindIR model by model conversion tool.
Create a Configuration Context: Create a configuration context Context and save some basic configuration parameters used to guide model compilation and model execution.
Model loading and compilation: Before executing inference, you need to call Build interface of Model for model loading and model compilation. The model loading phase parses the file cache into a runtime model. The model compilation phase can take more time so it is recommended that the model be created once, compiled once and perform inference about multiple times.
Input data: The input data needs to be padded before the model can be executed.
Execute inference: Use Predict of Model for model inference.
Preparation
The following code samples are from using C++ interface to perform cloud-side inference sample code.
Export the MindIR model via MindSpore, or get the MindIR model by converting it with model conversion tool and copy it to the
mindspore/lite/examples/cloud_infer/runtime_cpp/modeldirectory. You can download the MobileNetV2 model file mobilenetv2.mindir.Download the Ascend, Nvidia GPU, CPU triplet MindSpore Lite cloud-side inference package
mindspore- lite-{version}-linux-{arch}.tar.gzin the official website and save it tomindspore/lite/examples/cloud_infer/runtime_cppdirectory.
Creating Configuration Context
The context will save some basic configuration parameters used to guide model compilation and model execution.
The following sample code demonstrates how to create a Context.
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
Return a reference to the list of backend information for specifying the running device via MutableDeviceInfo. User-set device information is supported in MutableDeviceInfo, including CPUDeviceInfo, GPUDeviceInfo, AscendDeviceInfo. The number of devices set can only be one of them currently.
Configuring to Use the CPU Backend
When the backend to be executed is CPU, you need to set CPUDeviceInfo as the inference backend. Enable Float16 inference by SetEnableFP16.
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
auto cpu_device_info = std::make_shared<mindspore::CPUDeviceInfo>();
if (cpu_device_info == nullptr) {
std::cerr << "New CPUDeviceInfo failed." << std::endl;
return nullptr;
}
// CPU use float16 operator as priority.
cpu_device_info->SetEnableFP16(true);
device_list.push_back(cpu_device_info);
Optionally, you can additionally set the number of threads, thread affinity, parallelism strategy and other features.
Configure the number of threads
Context configure the number of threads via SetThreadNum:
// Configure the number of worker threads in the thread pool to 2, including the main thread. context->SetThreadNum(2);
Configure thread affinity
Context configure threads and CPU binding via SetThreadAffinity. Set the CPU binding list with the parameter
const std::vector<int> &core_list.// Configure the thread to be bound to the core list. context->SetThreadAffinity({0,1});
Configure parallelism strategy
Context configure the number of operator parallel inference at runtime via SetInterOpParallelNum.
// Configure the inference supports parallel. context->SetInterOpParallelNum(2);
Configuring Using GPU Backend
When the backend to be executed is GPU, you need to set GPUDeviceInfo as the inference backend. GPUDeviceInfo sets the device ID by SetDeviceID and enables Float16 inference by SetEnableFP16 or SetPrecisionMode.
The following sample code demonstrates how to create a GPU inference backend while the device ID is set to 0:
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
auto gpu_device_info = std::make_shared<mindspore::GPUDeviceInfo>();
if (gpu_device_info == nullptr) {
std::cerr << "New GPUDeviceInfo failed." << std::endl;
return nullptr;
}
// Set NVIDIA device id.
gpu_device_info->SetDeviceID(0);
// GPU use float16 operator as priority.
gpu_device_info->SetEnableFP16(true);
// The GPU device context needs to be push_back into device_list to work.
device_list.push_back(gpu_device_info);
Whether the SetEnableFP16 is set successfully depends on the [CUDA computing power] of the current device (https://docs.nvidia.com/deeplearning/tensorrt/support-matrix/index.html#hardware-precision-matrix).
SetPrecisionMode() has two parameters to control Float16 inference, SetPrecisionMode("preferred_fp16") equals to SetEnableFP16(true), vice versa.
SetPrecisionMode() |
SetEnableFP16() |
|---|---|
enforce_fp32 |
false |
preferred_fp16 |
true |
Configuring Using Ascend Backend
When the backend to be executed is Ascend (Ascend 310/310P/910 are currently supported), you need to set AscendDeviceInfo as the inference backend. AscendDeviceInfo sets the device ID by SetDeviceID. Ascend enables Float16 precision by default, and the precision mode can be changed by AscendDeviceInfo.SetPrecisionMode.
The following sample code demonstrates how to create Ascend inference backend while the device ID is set to 0:
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
// for Ascend 310/310P/910
auto device_info = std::make_shared<mindspore::AscendDeviceInfo>();
if (device_info == nullptr) {
std::cerr << "New AscendDeviceInfo failed." << std::endl;
return nullptr;
}
// Set Ascend 310/310P/910 device id.
device_info->SetDeviceID(device_id);
// The Ascend device context needs to be push_back into device_list to work.
device_list.push_back(device_info);
If the backend is Ascend deployed on the Elastic Cloud Server, use the SetProvider to set the provider to ge.
// Set the provider to ge.
device_info->SetProvider("ge");
The user can configure the precision mode by calling the SetPrecisionMode() interface, and the usage scenarios are shown in the following table:
user configure precision mode param |
ACL obtain precision mode param |
ACL scenario description |
|---|---|---|
enforce_fp32 |
force_fp32 |
force to use fp32 |
preferred_fp32 |
allow_fp32_to_fp16 |
prefer to use fp32 |
enforce_fp16 |
force_fp16 |
force to use fp16 |
enforce_origin |
must_keep_origin_dtype |
force to use original type |
preferred_optimal |
allow_mix_precision |
prefer to use fp16 |
Model Creation Loading and Compilation
When using MindSpore Lite to perform inference, Model is the main entry point for inference. Model loading, model compilation and model execution is implemented through model. Using the Context created in the previous step, call the compound Build interface of Model to implement model loading and model compilation.
The following sample code demonstrates the process of model creation, loading and compilation:
std::shared_ptr<mindspore::Model> BuildModel(const std::string &model_path, const std::string &device_type,
int32_t device_id) {
// Create and init context, add CPU device info
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
std::shared_ptr<mindspore::DeviceInfoContext> device_info = nullptr;
if (device_type == "CPU") {
device_info = CreateCPUDeviceInfo();
} else if (device_type == "GPU") {
device_info = CreateGPUDeviceInfo(device_id);
} else if (device_type == "Ascend") {
device_info = CreateAscendDeviceInfo(device_id);
}
if (device_info == nullptr) {
std::cerr << "Create " << device_type << "DeviceInfo failed." << std::endl;
return nullptr;
}
device_list.push_back(device_info);
// Create model
auto model = std::make_shared<mindspore::Model>();
if (model == nullptr) {
std::cerr << "New Model failed." << std::endl;
return nullptr;
}
// Build model
auto build_ret = model->Build(model_path, mindspore::kMindIR, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model failed." << std::endl;
return nullptr;
}
return model;
}
For large models, when using the model buffer to load and compile, you need to set the path of the weight file separately, sets the model path through LoadConfig or UpdateConfig interface, where
sectionismodel_ File,keyismindir_path. When using the model path to load and compile, you do not need to set other parameters. The weight parameters will be automatically read.
Inputting the Data
Before the model execution, the input data needs to be set, using the GetInputs method, which directly gets all vectors of the model input Tensor. You can get the size of the data that the Tensor should fill in by the DataSize method of the MSTensor. The data type of the Tensor can be obtained by the DataType. The input host data is set by SetData method.
There are currently two ways to specify input data:
By setting the input data via SetData, copying between hosts can be avoided and the input data will eventually be copied directly to the inference device.
int SetTensorHostData(std::vector<mindspore::MSTensor> *tensors, std::vector<MemBuffer> *buffers) { if (!tensors || !buffers) { std::cerr << "Argument tensors or buffers cannot be nullptr" << std::endl; return -1; } if (tensors->size() != buffers->size()) { std::cerr << "tensors size " << tensors->size() << " != " << " buffers size " << buffers->size() << std::endl; return -1; } for (size_t i = 0; i < tensors->size(); i++) { auto &tensor = (*tensors)[i]; auto &buffer = (*buffers)[i]; if (tensor.DataSize() != buffer.size()) { std::cerr << "Tensor data size " << tensor.DataSize() << " != buffer size " << buffer.size() << std::endl; return -1; } // set tensor data, and the memory should be freed by user tensor.SetData(buffer.data(), false); tensor.SetDeviceData(nullptr); } return 0; } auto inputs = model->GetInputs(); // Set the input data of the model, this inference input will be copied directly to the device. SetTensorHostData(&inputs, &input_buffer);
Copy the input data to the Tensor cache returned by MutableData. It should be noted that if the data address has been set by
SetData,MutableDatawill return the data address ofSetData, and you need to callSetData(nullptr)first.int CopyTensorHostData(std::vector<mindspore::MSTensor> *tensors, std::vector<MemBuffer> *buffers) { for (size_t i = 0; i < tensors->size(); i++) { auto &tensor = (*tensors)[i]; auto &buffer = (*buffers)[i]; if (tensor.DataSize() != buffer.size()) { std::cerr << "Tensor data size " << tensor.DataSize() << " != buffer size " << buffer.size() << std::endl; return -1; } auto dst_mem = tensor.MutableData(); if (dst_mem == nullptr) { std::cerr << "Tensor MutableData return nullptr" << std::endl; return -1; } memcpy(tensor.MutableData(), buffer.data(), buffer.size()); } return 0; } auto inputs = model->GetInputs(); // Set the input data of the model, copy data to the tensor buffer of Model.GetInputs. CopyTensorHostData(&inputs, &input_buffer);
Executing Inference
The Model.Predict interface is called to perform inference and subsequent processing of the returned output.
int SpecifyInputDataExample(const std::string &model_path, const std::string &device_type, int32_t device_id,
int32_t batch_size) {
auto model = BuildModel(model_path, device_type, device_id);
if (model == nullptr) {
std::cerr << "Create and build model failed." << std::endl;
return -1;
}
auto inputs = model->GetInputs();
// InferenceApp is user-defined code. Users need to obtain inputs and process outputs based on
// the actual situation.
InferenceApp app;
// Obtain inputs. The input data for inference may come from the preprocessing result.
auto &input_buffer = app.GetInferenceInputs(inputs);
if (input_buffer.empty()) {
return -1;
}
// Set the input data of the model, this inference input will be copied directly to the device.
SetTensorHostData(&inputs, &input_buffer);
std::vector<mindspore::MSTensor> outputs;
auto predict_ret = model->Predict(inputs, &outputs);
if (predict_ret != mindspore::kSuccess) {
std::cerr << "Predict error " << predict_ret << std::endl;
return -1;
}
// Process outputs.
app.OnInferenceResult(outputs);
return 0;
}
Compilation and Execution
Set the environment variables as described in the Environment Variables section in Quilk Start, and then compile the prograom as follows:
mkdir build && cd build
cmake ../
make
After successful compilation, you can get the runtime_cpp executable in the build directory. Execute program runtime_cpp to run the sample:
./runtime_cpp --model_path=../model/mobilenetv2.mindir --device_type=CPU
Advanced Usage
Dynamic Shape Input
Lite cloud-side inference framework supports dynamic shape input for models. GPU and Ascend hardware backend needs to be configured with dynamic input information during model conversion and model inference.
The configuration of dynamic input information is related to offline and online scenarios. For offline scenarios, the model conversion tool parameter --optimize=general, --optimize=gpu_oriented or --optimize=ascend_oriented, i.e. experiencing the hardware-related fusion and optimization. The generated MindIR model can only run on the corresponding hardware backend. For example, in Ascend 310 environment, if the model conversion tool specifies --optimize=ascend_oriented, the generated model will only support running on Ascend 310. If --optimize=general is specified, running on GPU and CPU is supported. For online scenarios, the loaded MindIR has not experienced hardware-related fusion and optimization, supports running on Ascend, GPU, and CPU. The model conversion tool parameter --optimize=none, or the MindSpore-exported MindIR model has not been processed by the conversion tool.
Ascend hardware backend offline scenarios require dynamic input information to be configured during the model conversion phase. Ascend hardware backend online scenarios, as well as GPU hardware backend offline and online scenarios, require dynamic input information to be configured during the model loading phase via the [LoadConfig](https://www.mindspore.cn/lite/api/en/r2.1/api_cpp/mindspore.html# loadconfig) interface.
An example configuration file loaded via LoadConfig is shown below:
[ascend_context]
input_shape=input_1:[-1,3,224,224]
dynamic_dims=[1~4],[8],[16]
[gpu_context]
input_shape=input_1:[-1,3,224,224]
dynamic_dims=[1~16]
opt_dims=[1]
The [ascend_context] and [gpu_context] act on the Ascend and GPU hardware backends, respectively.
Ascend and GPU hardware backends require dynamic input information for graph compilation and optimization, while CPU hardware backends do not require configuration of dynamic dimensional information.
input_shapeis used to indicate the input shape information in the formatinput_name1:[shape1];input_name2:[shape2]. If there are dynamic inputs, the corresponding dimension needs to be set to -1. Multiple inputs are separated by the English semicolon;.dynamic_dimsis used to indicate the value range of the dynamic dimension, with multiple non-contiguous ranges of values separated by the comma,. In the above example, Ascend batch dimension values range in1,2,3,4,8,16and GPU batch dimension values range from 1 to 16. Ascend hardware backend with dynamic inputs are in multi-step mode, the larger the dynamic input range, the longer the model compilation time.For the GPU hardware backend, additional configuration of
opt_dimsis required to indicate the optimal value in thedynamic_dimsrange.If
input_shapeis configured as a static shape,dynamic_dimsandopt_dimsdo not need to be configured.
Load the configuration file information via LoadConfig before the model Build:
// Create model
auto model = std::make_shared<mindspore::Model>();
if (model == nullptr) {
std::cerr << "New Model failed." << std::endl;
return nullptr;
}
if (!config_file.empty()) {
if (model->LoadConfig(config_file) != mindspore::kSuccess) {
std::cerr << "Failed to load config file " << config_file << std::endl;
return nullptr;
}
}
// Build model
auto build_ret = model->Build(model_path, mindspore::kMindIR, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model failed." << std::endl;
return nullptr;
}
In model inference, if the input to the model is dynamic and the input and output shape returned via GetInputs and GetOutputs may include -1, i.e., it is a dynamic shape, the input shape needs to be specified via the Resize interface. If the input Shape needs to change, for example, the batch dimension changes, the Resize interface needs to be called again to adjust the input Shape.
After calling the Resize interface, the shape of the Tensor in the called and subsequently called GetInputs and GetOutputs will be changed.
The following sample code demonstrates how to Resize the input Tensor of MindSpore Lite:
int ResizeModel(std::shared_ptr<mindspore::Model> model, int32_t batch_size) {
std::vector<std::vector<int64_t>> new_shapes;
auto inputs = model->GetInputs();
for (auto &input : inputs) {
auto shape = input.Shape();
shape[0] = batch_size;
new_shapes.push_back(shape);
}
if (model->Resize(inputs, new_shapes) != mindspore::kSuccess) {
std::cerr << "Failed to resize to batch size " << batch_size << std::endl;
return -1;
}
return 0;
}
Specifying Input and Output Host Memory
Specifies that device memory supports CPU, Ascend, and GPU hardware backends. The specified input host memory and the data in the cache will be copied directly to the device memory, and the data in the device memory will be copied directly to this cache for the specified output host memory. It avoids additional data copying between hosts and improves inference performance.
Input and output host memory can be specified separately or simultaneously by SetData. It is recommended that the parameter own_data be false. When own_data is false, the user needs to maintain the life cycle of host memory and is responsible for the request and release of host memory. When the parameter own_data is true, the specified memory is freed at the MSTensor destruct.
Specify input host memory
The values of input host memory are generally derived from the preprocessing results of C++ and Python on the host side.
std::vector<void *> host_buffers; // ... get host buffer from preprocessing etc. // Get Input auto inputs = model->GetInputs(); for (size_t i = 0; i < tensors.size(); i++) { auto &tensor = tensors[i]; auto host_data = host_buffers[i]; tensor.SetData(host_data, false); tensor.SetDeviceData(nullptr); } std::vector<mindspore::MSTensor> outputs; if (model->Predict(inputs, &outputs) != 0) { return -1; }
Specify output host memory
// Get Output from model auto outputs = model->GetOutputs(); std::vector<void *> output_buffers; ResourceGuard output_device_rel([&output_buffers]() { for (auto &item : output_buffers) { free(item); } }); for (auto &tensor : outputs) { auto buffer = malloc(tensor.DataSize()); tensor.SetData(buffer, false); tensor.SetDeviceData(nullptr); output_buffers.push_back(buffer); // for free } if (model->Predict(inputs, &outputs) != 0) { return -1; }
Specifying the Memory of the Input and Output Devices
Specifying device memory supports Ascend and GPU hardware backends. Specifying input and output device memory can avoid mutual copying from device to host memory, for example, the device memory input generated by chip dvpp preprocessing is directly used as input for model inference, avoiding preprocessing results copied from device memory to host memory and host results used as model inference input and re-copied to device before inference.
Sample memory for specified input and output devices can be found in sample device memory.
Input and output device memory can be specified separately or simultaneously by SetDeviceData. The user needs to maintain the device memory lifecycle and is responsible for device memory requests and releases.
Specify the input device memory
In the sample, the value of the input device memory is copied from host, and the value of the general device memory comes from the preprocessing result of chip or the output of another model.
int SetDeviceData(std::vector<mindspore::MSTensor> tensors, const std::vector<uint8_t *> &host_data_buffer, std::vector<void *> *device_buffers) { for (size_t i = 0; i < tensors.size(); i++) { auto &tensor = tensors[i]; auto host_data = host_data_buffer[i]; auto data_size = tensor.DataSize(); if (data_size == 0) { std::cerr << "Data size cannot be 0, tensor shape: " << ShapeToString(tensor.Shape()) << std::endl; return -1; } auto device_data = MallocDeviceMemory(data_size); if (device_data == nullptr) { std::cerr << "Failed to alloc device data, data size " << data_size << std::endl; return -1; } device_buffers->push_back(device_data); if (CopyMemoryHost2Device(device_data, data_size, host_data, data_size) != 0) { std::cerr << "Failed to copy data to device, data size " << data_size << std::endl; return -1; } tensor.SetDeviceData(device_data); tensor.SetData(nullptr, false); } return 0; } // Get Input auto inputs = model->GetInputs(); std::vector<void *> device_buffers; ResourceGuard device_rel([&device_buffers]() { for (auto &item : device_buffers) { FreeDeviceMemory(item); } }); SetDeviceData(inputs, host_buffers, &device_buffers); std::vector<mindspore::MSTensor> outputs; if (Predict(model, inputs, &outputs) != 0) { return -1; }
Specify the output device memory
In the sample, the output device memory is copied to the host and prints the output. Generally the output device memory can be used as input for other models.
int SetOutputDeviceData(std::vector<mindspore::MSTensor> tensors, std::vector<void *> *device_buffers) { for (size_t i = 0; i < tensors.size(); i++) { auto &tensor = tensors[i]; auto data_size = tensor.DataSize(); if (data_size == 0) { std::cerr << "Data size cannot be 0, tensor shape: " << ShapeToString(tensor.Shape()) << std::endl; return -1; } auto device_data = MallocDeviceMemory(data_size); if (device_data == nullptr) { std::cerr << "Failed to alloc device data, data size " << data_size << std::endl; return -1; } device_buffers->push_back(device_data); tensor.SetDeviceData(device_data); tensor.SetData(nullptr, false); } return 0; } // Get Output from model auto outputs = model->GetOutputs(); std::vector<void *> output_device_buffers; ResourceGuard output_device_rel([&output_device_buffers]() { for (auto &item : output_device_buffers) { FreeDeviceMemory(item); } }); if (SetOutputDeviceData(outputs, &output_device_buffers) != 0) { std::cerr << "Failed to set output device data" << std::endl; return -1; } if (Predict(model, inputs, &outputs) != 0) { return -1; }
Ascend Backend GE Inference
Ascend inference currently has two methods.
The first method is the default ACL inference. The ACL interface only has global and model (graph) level option configurations. So multiple graphs cannot indicate association relationships, they are relatively independent and cannot share weights (including constants and variables). If there are variables, which can be changed in the model, variables need to be initialized first, so an additional initialization graph needs to be constructed and executed, and variables need to be shared with the calculation graph. Due to the relative independence of multiple graphs, the model cannot have variables when using default ACL inference.
The ACL interface supports building models in advance and loading them using already built models.
Another method is the GE inference. The GE interface has global, session and model (graph) level option configurations. Multiple graphs can be in the same session, and can share weights. In the same session, initialization graphs can be created for variables and shared with computational graphs. When using the default GE inference, the model can have variables.
The current GE interface does not support building models in advance, and models need to be built during loading.
GE can be enabled by specifying provider as ge.
import mindspore_lite as mslite
context = mslite.Context()
context.target = ["Ascend"]
context.ascend.device_id = 0
context.ascend.rank_id = 0
context.ascend.provider = "ge"
model = mslite.Model()
model.build_from_file("seq_1024.mindir", mslite.ModelType.MINDIR, context, "config.ini")
auto device_info = std::make_shared<mindspore::AscendDeviceInfo>();
if (device_info == nullptr) {
std::cerr << "New AscendDeviceInfo failed." << std::endl;
return -1;
}
// Set Ascend 910 device id, rank id and provider.
device_info->SetDeviceID(0);
device_info->SetRankID(0);
device_info->SetProvider("ge");
// Device context needs to be push_back into device_list to work.
device_list.push_back(device_info);
mindspore::Model model;
if (model.LoadConfig("config.ini") != mindspore::kSuccess) {
std::cerr << "Failed to load config file " << "config.ini" << std::endl;
return -1;
}
// Build model
auto build_ret = model.Build("seq_1024.mindir", mindspore::kMindIR, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model error " << build_ret << std::endl;
return -1;
}
In the configuration file, the options from [ge_global_options], [ge_sesion_options] and [ge_graph_options] will be used as global, session and model (graph) level options for the GE interface. For details, please refer to GE Options. For example:
[ge_global_options]
ge.opSelectImplmode=high_precision
[ge_session_options]
ge.externalWeight=1
[ge_graph_options]
ge.exec.precision_mode=allow_fp32_to_fp16
ge.inputShape=x1:-1,3,224,224;x2:-1,3,1024,1024
ge.dynamicDims=1,1;2,2;3,3;4,4
ge.dynamicNodeType=1
Loading Models through Multiple Threads
When the backend is Ascend and the provider is the default, it supports loading multiple Ascend optimized models through multiple threads to improve model loading performance. Using the Model converting tool, we can specify --optimize=ascend_oriented to convert MindIR models exported from MindSpore, third-party framework models such as TensorFlow and ONNX into Ascend optimized models. The MindIR models exported by MindSpore have not undergone Ascend optimization. For third-party framework models, the MindIR model generated by specifying --optimize=none in the converting tool has not undergone Ascend optimization.
Multiple Models Sharing Weights
In the Ascend device GE scenario, a single device can deploy multiple models, and models deployed in the same device can share weights, including constants and variables.
The same model script can export different models with the same weights for different conditional branches or input shapes. During the inference process, some weights can no longer be updated and are parsed as constants, where multiple models will have the same constant weights, while some weights may be updated and are parsed as variables. If one model updates one weight, the modified weight can be use and updated in the next inference or by other models.
The relationship between multiple models sharing weights can be indicated through interface ModelGroup.
Python implementation:
def load_model(model_path0, model_path1, config_file_0, config_file_1, rank_id, device_id):
context = mslite.Context()
context.ascend.device_id = device_id
context.ascend.rank_id = rank_id # for distributed model
context.ascend.provider = "ge"
context.target = ["Ascend"]
model0 = mslite.Model()
model1 = mslite.Model()
model_group = mslite.ModelGroup(mslite.ModelGroupFlag.SHARE_WEIGHT)
model_group.add_model([model0, model1])
model0.build_from_file(model_path0, mslite.ModelType.MINDIR, context, config_file_0)
model1.build_from_file(model_path1, mslite.ModelType.MINDIR, context, config_file_1)
return model0, model1
C++ implementation:
std::vector<Model> LoadModel(const std::string &model_path0, const std::string &model_path1,
const std::string &config_file_0, const std::string &config_file_1,
uint32_t rank_id, uint32_t device_id) {
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return {};
}
auto &device_list = context->MutableDeviceInfo();
auto device_info = std::make_shared<mindspore::AscendDeviceInfo>();
if (device_info == nullptr) {
std::cerr << "New AscendDeviceInfo failed." << std::endl;
return {};
}
device_info->SetDeviceID(device_id);
device_info->SetRankID(rank_id);
device_info->SetProvider("ge");
device_list.push_back(device_info);
mindspore::Model model0;
mindspore::Model model1;
mindspore::ModelGroup model_group(mindspore::ModelGroupFlag::kShareWeight);
model_group.AddModel({model0, model1});
if (!model0.LoadConfig(config_file_0).IsOk()) {
std::cerr << "Failed to load config file " << config_file_0 << std::endl;
return {};
}
if (!model0.Build(model_path0, mindspore::ModelType::kMindIR, context).IsOk()) {
std::cerr << "Failed to load model " << model_path0 << std::endl;
return {};
}
if (!model1.LoadConfig(config_file_1).IsOk()) {
std::cerr << "Failed to load config file " << config_file_1 << std::endl;
return {};
}
if (!model1.Build(model_path1, mindspore::ModelType::kMindIR, context).IsOk()) {
std::cerr << "Failed to load model " << model_path1 << std::endl;
return {};
}
return {model0, model1};
}
By default, multiple models in the above configuration only share variables. When constants need to be shared, the weight externalization option needs to be configured in the configuration file. The configuration files are the config_file_0 and config_file_1 of the above examples.
[ge_session_options]
ge.externalWeight=1