应用SimQAT算法
![]()
背景
SimQAT是一种最基础的感知量化算法,其具体原理来源于谷歌的量化白皮书,是一种基于伪量化节点的感知量化算法。
伪量化节点
伪量化节点,是指感知量化训练时,往网络中插入的一类节点,其用途是寻找网络数据分布,并反馈损失精度,具体作用如下:
找到参数的分布,即找到待量化参数的最大值和最小值;
模拟量化为低比特时的精度损失,把该损失作用到网络中,传递给损失函数,让优化器在训练过程中对该损失值进行优化。
BatchNorm折叠
为了归一化输出数据,卷积或者全连接层后通常会加入BatchNorm算子,在训练阶段BatchNorm作为一个独立的算子,统计输出的均值和方差(如下左图),在推理阶段则将其融入权重和Bias中,称为BatchNorm折叠(如下右图)。

BatchNorm折叠的公式如下:
在感知量化训练中,为精确模拟推理中的折叠操作,论文[1]使用两套卷积分别用于计算当前的BatchNorm参数,并用计算得到的参数归一化实际作用卷积的权重值(如下左图),其中CorrectionMul用于权重校正,MulFold用于权重数据归一化。在MindSpore Golden Stick中会进一步将权重校正和权重数据融合(如下右图),提升训练性能。
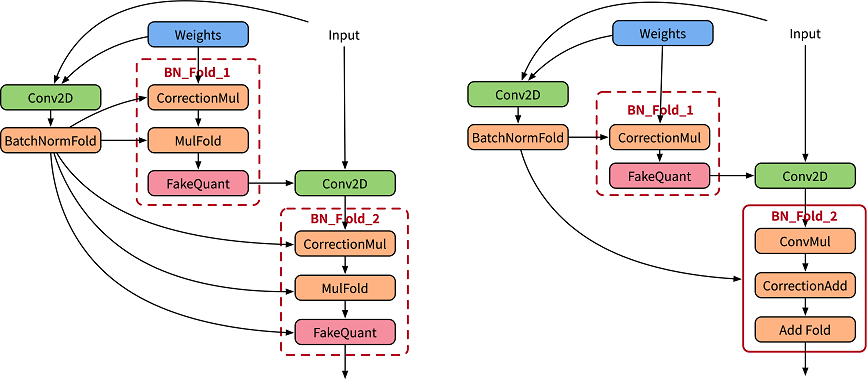
感知量化训练
MindSpore的感知量化训练是指在训练时使用伪量化节点来模拟量化操作,过程中仍然采用浮点数计算,并通过反向传播学习更新网络参数,使得网络参数更好地适应量化带来的损失。对于权值和数据的量化,MindSpore采用了参考文献[1]中的方案。
表1:感知量化训练规格
规格 |
规格说明 |
|---|---|
硬件支持 |
GPU |
网络支持 |
LeNet、ResNet50,具体请参见https://gitee.com/mindspore/models/tree/r2.0.0-alpha。 |
算法支持 |
支持非对称和对称的量化算法;支持逐层和逐通道的量化算法。 |
方案支持 |
支持8比特的量化方案。 |
数据类型支持 |
GPU平台支持FP32。 |
运行模式支持 |
Graph模式和PyNative模式 |
感知量化训练示例
感知量化训练与一般训练步骤基本一致,在构造网络阶段需要应用MindSpore Golden Stick的量化算法生成量化网络,完整流程如下:
加载数据集,处理数据。
定义网络。
定义MindSpore Golden Stick量化算法,应用算法生成量化网络。
定义优化器、损失函数和callbacks。
训练网络,保存checkpoint文件。
评估网络,对比量化后精度。
接下来以LeNet5网络为例,分别叙述这些步骤。
加载数据集
调用MindData加载数据集:
ds_train = create_dataset(os.path.join(config.data_path), config.batch_size)
代码中create_dataset引用自dataset.py ,config.data_path和config.batch_size分别在配置文件 中配置,下同。
定义原网络
实例化LeNet5网络:
from src.lenet import LeNet5
...
network = LeNet5(config.num_classes)
print(network)
原始网络结构如下:
LeNet5<
(conv1): Conv2d<input_channels=1, output_channels=6, kernel_size=(5, 5), stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, has_bias=False, weight_init=normal, bias_init=zeros, format=NCHW>
(conv2): Conv2d<input_channels=6, output_channels=16, kernel_size=(5, 5), stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, has_bias=False, weight_init=normal, bias_init=zeros, format=NCHW>
(relu): ReLU<>
(max_pool2d): MaxPool2d<kernel_size=2, stride=2, pad_mode=VALID>
(flatten): Flatten<>
(fc1): Dense<input_channels=400, output_channels=120, has_bias=True>
(fc2): Dense<input_channels=120, output_channels=84, has_bias=True>
(fc3): Dense<input_channels=84, output_channels=10, has_bias=True>
>
LeNet5网络定义见lenet.py 。
应用量化算法
量化网络是指在原网络定义的基础上,修改需要量化的网络层后生成的带有伪量化节点的网络,通过构造MindSpore Golden Stick下的SimulatedQuantizationAwareTraining类,并将其应用到原网络上将原网络转换为量化网络。
from mindspore_gs import SimulatedQuantizationAwareTraining as SimQAT
...
algo = SimQAT()
quanted_network = algo.apply(network)
print(quanted_network)
量化网络结构如下,其中QuantizerWrapperCell为感知量化训练对原有Conv2d或者Dense的封装类,包括了原有的算子以及输入输出和权重的伪量化节点,用户可以参考API 修改算法配置,并通过检查QuantizeWrapperCell的属性确认算法是否配置成功。
LeNet5Opt<
(_handler):
...
(Conv2dQuant): QuantizeWrapperCell<
(_handler): Conv2dQuant<
in_channels=1, out_channels=6, kernel_size=(5, 5), stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, has_bias=False
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 6), quant_delay=0>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
>
(Conv2dQuant_1): QuantizeWrapperCell<
(_handler): Conv2dQuant<
in_channels=6, out_channels=16, kernel_size=(5, 5), stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, has_bias=False
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 16), quant_delay=0>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
>
(DenseQuant): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=400, out_channels=120, weight=Parameter (name=DenseQuant._handler.weight, shape=(120, 400), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant._handler.bias, shape=(120,), dtype=Float32, requires_grad=True)
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 120), quant_delay=0>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
>
(DenseQuant_1): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=120, out_channels=84, weight=Parameter (name=DenseQuant_1._handler.weight, shape=(84, 120), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant_1._handler.bias, shape=(84,), dtype=Float32, requires_grad=True)
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 84), quant_delay=0>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
>
(DenseQuant_2): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=84, out_channels=10, weight=Parameter (name=DenseQuant_2._handler.weight, shape=(10, 84), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant_2._handler.bias, shape=(10,), dtype=Float32, requires_grad=True)
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 10), quant_delay=0>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=0>
>
>
定义优化器、损失函数和训练的callbacks
使用Momentum作为LeNet5网络训练的优化器;使用SoftmaxCrossEntropyWithLogits作为LeNet5网络训练的损失函数:
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
net_opt = nn.Momentum(network.trainable_params(), config.lr, config.momentum)
time_cb = TimeMonitor(data_size=ds_train.get_dataset_size())
config_ck = CheckpointConfig(save_checkpoint_steps=config.save_checkpoint_steps,
keep_checkpoint_max=config.keep_checkpoint_max)
ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory="./ckpt", config=config_ck)
训练网络,保存checkpoint文件
调用Model中的train接口开始训练模型:
model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()})
model.train(config.epoch_size, ds_train, callbacks=[time_cb, ckpoint_cb, LossMonitor()])
运行结果如下:
epoch:1 step: 1875, loss is 0.1609785109
Train epoch time: 18172.836 ms, per step time: 9.692 ms
epoch:2 step: 1875, loss is 0.00334590533
Train epoch time: 8617.408 ms, per step time: 4.596 ms
epoch:3 step: 1875, loss is 0.00310735423
Train epoch time: 8526.766 ms, per step time: 4.548 ms
epoch:4 step: 1875, loss is 0.00962805934
Train epoch time: 8585.520 ms, per step time: 4.579 ms
epoch:5 step: 1875, loss is 0.00363082927
Train epoch time: 8512.096 ms, per step time: 4.540 ms
epoch:6 step: 1875, loss is 0.00169560452
Train epoch time: 8303.8515 ms, per step time: 4.429 ms
epoch:7 step: 1875, loss is 0.08799523115
Train epoch time: 8417.257 ms, per step time: 4.489 ms
epoch:8 step: 1875, loss is 0.0838107979
Train epoch time: 8416.146 ms, per step time: 4.489 ms
epoch:9 step: 1875, loss is 0.00722093607
Train epoch time: 8425.732 ms, per step time: 4.484 ms
epoch:10 step: 1875, loss is 0.00027961225
Train epoch time: 8544.641 ms, per step time: 4.552 ms
评估网络,对比精度
按照lenet模型仓 步骤获得普通训练的模型精度:
'Accuracy':0.9842
加载上一步得到的checkpoint文件,并评估量化模型的精度。
param_dict = load_checkpoint(config.checkpoint_file_path)
load_param_into_net(network, param_dict)
ds_eval = create_dataset(os.path.join(config.data_path), config.batch_size)
acc = model.eval(ds_eval)
print(acc)
'Accuracy':0.990484
LeNet5应用感知量化训练后精度未下降。
感知量化算法的一个效果是压缩模型大小,但这里提到的模型大小是指部署模型的大小。此处的网络并非最终的部署模型,又由于网络中增加了伪量化节点,所以量化网络的checkpoint文件大小反而相较原始网路的略有增加。
总结
本文主要介绍了量化的作用、常用量化算法的原理,并给出了示例介绍如何应用MindSpore Golden Stick中的感知量化算法。量化算法可以在精度不下降或者下降较少的前提下大幅降低模型尺寸,提升模型推理性能,欢迎使用MindSpore Golden Stick的感知量化训练功能!
参考文献
[1] Jacob B, Kligys S, Chen B, et al. Quantization and training of neural networks for efficient integer-arithmetic-only inference[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2704-2713.