应用RoundToNearest后量化算法
![]()
RoundToNearest后量化算法简介
RoundToNearest算法是一类较朴素的后量化算法,其取整方式采用Round to nearest,即四舍五入的方式。
当前金箍棒中的RoundToNearest后量化(以下简称RTN)主要针对LLM(大语言模型)场景。该算法使用MinMax校正器对线性层(Linear)进行量化。伪量化的网络结构示意如下:
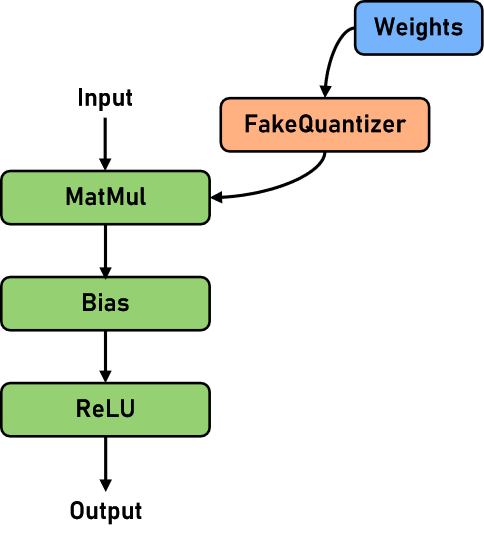
表1:RTN算法规格
规格 |
规格说明 |
|---|---|
硬件支持 |
量化阶段运行在CPU,量化模型推理仅支持Ascend |
网络支持 |
Llama2系列网络,具体请参见Llama2网络 |
运行模式支持 |
Graph模式和PyNative模式 |
表2:网络使用RTN算法量化前后对比
指标 | llama2-7B | llama2-13B | llama2-70B | baichuan2-13B | chatGLM3-6B | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
FP16 | W8A16 | 收益 | FP16 | W8A16 | 收益 | FP16 | W8A16 | 收益 | FP16 | W8A16 | 收益 | FP16 | W8A16 | 收益 | |
ckpt-size(GB)↓ | 13 | 7.1 | -45.38% | 25 | 14 | -44.00% | 129 | 65 | -49.61% | 26 | 15 | -42.31% | 12 | 6.1 | -49.17% |
wikitext2-Perplexity↓ | 15.130 | 15.129 | 0.00 | 14.18 | 14.203 | 0.02 | 10.379 | 10.435 | 0.046 | 23.955 | 23.912 | -0.043 | |||
squad1.1-F1↑ | 60.48 | 60.76 | 0.28 | ||||||||||||
squad1.1-EM↑ | 39.62 | 39.57 | -0.05 | ||||||||||||
全量性能(tokens/s) | 9.08 | 9.04 | 0 | ||||||||||||
增量性能(tokens/s) | 30.24 | 21.08 | -30.29% | ||||||||||||
显存(GB) | 27 | 16 | -40.7% | ||||||||||||
示例
跟金箍棒仓库中所有算法一样,RTN算法的应用主要可以分为两个阶段:量化阶段和部署阶段。
量化阶段在部署前完成,主要工作包括:收集权重分布、计算量化参数、量化权重数据、插入反量化节点。
部署阶段通常是指用户在生产环境中,使用MindSpore框架对量化后的模型进行推理的过程。
本用例使用Llama2网络进行演示,主要分四个步骤:环境准备、模型量化、模型部署评估、效果分析。
步骤1. 环境准备
1.1. Ascend环境
RTN算法需要运行在Ascend硬件上,Ascend的环境配置可以参考MindSpore安装指南中的“安装昇腾AI处理器配套软件包”小节和“配置环境变量”小节。
1.2. MindSpore环境
金箍棒依赖MindSpore,需要提前安装对应版本。可以从MindSpore官网下载预编译好的版本安装包并安装。
1.3. MindFormers环境
金箍棒依赖MindFormers,需要提前安装对应版本。可以从MindSpore官网下载预编译好的MindFormers版本安装包并安装。
1.4. 金箍棒环境
从MindSpore官网下载预编译好的版本安装包并安装。
1.5. 相关文件准备
需要预先下载MindSpore Transformers Llama2网络相关的文件以及评估使用的数据集,包括:wikitext2数据集和Llama2 7B网络相关文件。
第一步创建工作目录:
[1]:
!mkdir workspace
第二步准备数据集:
数据集下载地址:WikiText2数据集
下载数据集后,需要将数据集文件拷贝到上一步创建的workspace目录下,并确保数据集文件名为wikitext-2-v1.zip,然后运行解压代码:
[2]:
!cd workspace; unzip wikitext-2-v1.zip
Archive: wikitext-2-v1.zip
creating: wikitext-2/
inflating: wikitext-2/wiki.test.tokens
inflating: wikitext-2/wiki.valid.tokens
inflating: wikitext-2/wiki.train.tokens
第三步准备Llama2 7B网络checkpoint文件、Llama2分词器文件、Llama2模型配置文件:
[ ]:
!cd workspace; wget --no-check-certificate -O llama2_7b.ckpt https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/MindFormers/llama2/llama2_7b.ckpt
!cd workspace; wget --no-check-certificate -O tokenizer.model https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/MindFormers/llama2/tokenizer.model
!cd workspace; cp ../configs/predict_llama2_7b.yaml ./
--2024-03-19 17:29:17-- https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/MindFormers/llama2/llama2_7b.ckpt
Length: 13476850247 (13G) [binary/octet-stream]
Saving to: ‘llama2_7b.ckpt’
llama2_7b.ckpt 100%[===================>] 12.55G 27.5MB/s in 7m 39s
2024-03-19 17:36:57 (28.0 MB/s) - ‘llama2_7b.ckpt’ saved [13476850247/13476850247]
--2024-03-19 17:36:57-- https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/MindFormers/llama2/tokenizer.model
Length: 499723 (488K) [binary/octet-stream]
Saving to: ‘tokenizer.model’
tokenizer.model 100%[===================>] 488.01K --.-KB/s in 0.1s
2024-03-19 17:36:57 (3.37 MB/s) - ‘tokenizer.model’ saved [499723/499723]
下载时如果遇到网络问题,可以尝试使用浏览器手动下载相应文件,并放到相应目录下
第四步修改predict_llama2_7b.yaml文件,将checkpoint、tokenizer的路径分别覆盖到yaml配置文件中load_checkpoint字段和processor章节的vocab_file字段。同时修改context章节的device_id为当前机器空闲的设备id。
完成上述准备后,检查目录结构:
[4]:
!cd workspace; tree -L 2 -U
.
├── llama2_7b.ckpt
├── wikitext-2
│ ├── wiki.train.tokens
│ ├── wiki.test.tokens
│ └── wiki.valid.tokens
├── tokenizer.model
├── wikitext-2-v1.zip
└── predict_llama2_7b.yaml
1 directory, 7 files
步骤2. 模型量化
构造MindSpore Transformers仓库的Llama2网络,然后使用金箍棒RoundToNearest算法对网络进行量化,最终保存量化后的checkpoint文件:
[ ]:
import os
import time
import mindspore as ms
from mindformers import LlamaForCausalLM, MindFormerConfig, LlamaConfig, init_context
from mindspore_gs.ptq import PTQMode, PTQConfig
from mindspore_gs.common import BackendTarget, logger
from mindspore_gs.ptq import RoundToNearest as RTN
from mindspore_gs.ptq.network_helpers.mf_net_helpers import MFLlama2Helper
class Llama2Network:
"""Llama2Network."""
@staticmethod
def create_mfconfig(config_path):
"""Create mindformers config for llama2 network for example."""
config = MindFormerConfig(config_path)
config.model.model_config = LlamaConfig(**config.model.model_config)
init_context(use_parallel=config.use_parallel, context_config=config.context, parallel_config=config.parallel)
return config
@staticmethod
def create_network(mindformers_config):
network = LlamaForCausalLM(mindformers_config.model.model_config)
network.set_train(False)
network.phase = 'predict'
return network
def quant_network(net: LlamaForCausalLM, mode=PTQMode.QUANTIZE, backend=BackendTarget.ASCEND, **kwargs):
"""Quant llama2 model to w8a16 with RTN algorithm."""
start_time = time.time()
if mode == PTQMode.QUANTIZE:
logger.info("Use RTN algo to quant network and weight.")
else:
logger.info("Use RTN algo to quant network.")
cfg = PTQConfig(mode=mode, backend=backend, opname_blacklist=["lm_head"])
ptq = RTN(config=cfg)
logger.info(f'Create PTQ cost time is {time.time() - start_time} s.')
start_time = time.time()
mfconfig = kwargs.get("mfconfig", None)
if not mfconfig:
raise ValueError("Please provide mfconfig for calibrating.")
network_helper = MFLlama2Helper(mfconfig)
net = ptq.apply(net, network_helper)
logger.info(f'Apply PTQ cost time is {time.time() - start_time} s.')
start_time = time.time()
net.phase = "quant_convert"
net = ptq.convert(net)
logger.info(f'Convert to real quantize cost time is {time.time() - start_time} s.')
return net
start = time.time()
print('------------------------- Creating network...', flush=True)
net_mgr: Llama2Network = Llama2Network()
config = net_mgr.create_mfconfig("./workspace/predict_llama2_7b.yaml")
network = net_mgr.create_network(config)
logger.info(f'Create Network cost time is {time.time() - start} s.')
start = time.time()
ckpt_path = config.load_checkpoint
logger.info(f'Loading ckpt :{ckpt_path}.')
ms.load_checkpoint(ckpt_path, network)
ms.ms_memory_recycle()
logger.info(f'Load ckpt cost time is {time.time() - start} s.')
print('------------------------- Quantize-ing network...', flush=True)
start = time.time()
network = quant_network(network, mode=PTQMode.QUANTIZE, backend=BackendTarget.ASCEND, mfconfig=config)
logger.info(f'Quant Network cost time is {time.time() - start} s.')
print('------------------------- Saving checkpoint...', flush=True)
start = time.time()
save_ckpt_path = os.path.join(config.output_dir, "w8a16_ckpt")
save_path = os.path.join(save_ckpt_path, f"rank_0")
os.makedirs(save_path, exist_ok=True)
ms.save_checkpoint(network.parameters_dict(), os.path.join(save_path, "w8a16.ckpt"),
choice_func=lambda x: "key_cache" not in x and "value_cache" not in x)
logger.info(f'Save checkpoint cost time is {time.time() - start} s.')
print(f'------------------------- Checkpoint saved to {save_path}...', flush=True)
------------------------- Quantize-ing network...
2024-03-19 19:19:37,711 - mindformers[mindformers/models/llama/llama.py:359] - INFO - Predict run mode:True
------------------------- Quantize-ing network...
2024-03-19 19:37:11,103 - mindformers[mindformers/generation/text_generator.py:914] - INFO - total time: 53.80364537239075 s; generated tokens: 1 tokens; generate speed: 0.018586101240514612 tokens/save_checkpoint
------------------------- Saving checkpoint...
------------------------- Checkpoint saved to ./output/w8a16_ckpt/rank_0/...
成功运行后,量化后的checkpoint文件会保存在 ./output/w8a16_ckpt/rank_0/w8a16.ckpt 路径下。
步骤3. 模型部署
3.1. 评估FP16网络的Perplexity指标
使用WikiText2数据集评估Llama2-7B网络的困惑度指标。在评估前,需要注意环境中没有配置RUN_MODE环境变量。
[ ]:
import mindspore as ms
from mindformers.core.metric import PerplexityMetric
from mindspore_gs.datasets import create_wikitext_dataset
from mindspore_gs.ptq.network_helpers.mf_net_helpers import MFLlama2Helper
net_mgr: Llama2Network = Llama2Network()
fp16_network_config = net_mgr.create_mfconfig("./workspace/predict_llama2_7b.yaml")
fp16_network_config.model.model_config.use_past = False
pad_token_id = fp16_network_config.model.model_config.pad_token_id
fp16_network = net_mgr.create_network(fp16_network_config)
ms.load_checkpoint(fp16_network_config.load_checkpoint, fp16_network)
net_helper = MFLlama2Helper(fp16_network_config)
bs = net_helper.get_spec("batch_size")
seq_len = net_helper.get_spec("seq_length")
tokenizer = net_helper.create_tokenizer()
fp16_ds = create_wikitext_dataset("./workspace/wikitext-2/wiki.valid.tokens", bs, seq_len, max_new_tokens=1, tokenizer=tokenizer)
metric = PerplexityMetric()
metric.clear()
data_count = 0
total_count = fp16_ds.get_dataset_size()
for _, ds_item in enumerate(fp16_ds.create_dict_iterator()):
data_count += 1
logger.info(f"Dataset count: {data_count}/{total_count}")
input_ids = ds_item['input_ids'].asnumpy()
net_inputs = net_helper.assemble_inputs(input_ids)
outputs = fp16_network(*net_inputs)
metric.update(*outputs)
print('...........Evaluate Over!...............', flush=True)
print(f"FP16 PPL: {metric.eval()}", flush=True)
......
2024-03-19 19:41:52,132 - mindformers[mindformers/models/modeling_utils.py:1413] - INFO - weights in ./workspace/llama2_7b.ckpt are loaded
[INFO] GE(2617230,python):2024-03-19-19:42:00.316.847 [ge_api.cc:523][status:INIT]2617230 AddGraph:Start to add graph in Session. graph_id: 1, graph_name: kernel_graph0, session_id: 0.
[INFO] GE(2617230,python):2024-03-19-19:42:00.317.200 [ge_api.cc:1154][status:INIT]2617230 CompileGraph:Start to compile graph, graph_id: 1
[INFO] GE(2617230,python):2024-03-19-19:42:00.317.282 [graph_manager.cc:1264][EVENT]2617230 PreRun:PreRun start: graph node size 1, session id 0, graph id 1, graph name kernel_graph0.
......
[INFO] GE(2617230,python):2024-03-19-19:43:17.424.380 [ge_api.cc:787][status:INIT]2654383 RunGraphWithStreamAsync:Session run graph with stream async, session_id: 0, graph_id: 2, input size 291, output size 3
[INFO] GE(2617230,python):2024-03-19-19:43:17.424.812 [ge_api.cc:799][status:STOP]2654383 RunGraphWithStreamAsync:Session run graph with stream async finished.
[INFO] GE(2617230,python):2024-03-19-19:43:17.464.158 [ge_api.cc:787][status:INIT]2654383 RunGraphWithStreamAsync:Session run graph with stream async, session_id: 0, graph_id: 3, input size 3, output size 1
[INFO] GE(2617230,python):2024-03-19-19:43:17.464.296 [ge_api.cc:799][status:STOP]2654383 RunGraphWithStreamAsync:Session run graph with stream async finished.
FP16 PPL: {'PerplexityMetric': {'loss': 2.247190694278072, 'PPL': 9.460511724873594}}
3.2. 实例化非量化Llama2网络
[ ]:
import mindspore as ms
from mindformers.core.metric import PerplexityMetric
from mindspore_gs.datasets import create_wikitext_dataset
from mindspore_gs.ptq.network_helpers.mf_net_helpers import MFLlama2Helper
net_mgr: Llama2Network = Llama2Network()
network_config = net_mgr.create_mfconfig("./workspace/predict_llama2_7b.yaml")
network_config.model.model_config.use_past = False
pad_token_id = network_config.model.model_config.pad_token_id
w8a16_network = net_mgr.create_network(network_config)
2024-03-19 19:19:37,710 - mindformers[mindformers/version_control.py:62] - INFO - The Cell Reuse compilation acceleration feature is not supported when the environment variable ENABLE_CELL_REUSE is 0 or MindSpore version is earlier than 2.1.0 or stand_alone mode or pipeline_stages <= 1
2024-03-19 19:19:37,710 - mindformers[mindformers/version_control.py:66] - INFO -
The current ENABLE_CELL_REUSE=0, please set the environment variable as follows:
export ENABLE_CELL_REUSE=1 to enable the Cell Reuse compilation acceleration feature.
2024-03-19 19:19:37,711 - mindformers[mindformers/version_control.py:72] - INFO - The Cell Reuse compilation acceleration feature does not support single-card mode.This feature is disabled by default. ENABLE_CELL_REUSE=1 does not take effect.
2024-03-19 19:19:37,712 - mindformers[mindformers/version_control.py:75] - INFO - The Cell Reuse compilation acceleration feature only works in pipeline parallel mode(pipeline_stage>1).Current pipeline stage=1, the feature is disabled by default.
2024-03-19 19:21:07,859 - mindformers[mindformers/models/modeling_utils.py:1415] - INFO - model built, but weights is unloaded, since the config has no checkpoint_name_or_path attribute or checkpoint_name_or_path is None.
3.3. 加载量化后的ckpt
由于MindSpore当前不支持保存修改后的网络,所以在加载量化ckpt之前,需要先用算法恢复带量化结构的网络,然后再加载ckpt到网络。
[11]:
deploy_cfg = PTQConfig(mode=PTQMode.DEPLOY, backend=BackendTarget.ASCEND, opname_blacklist=["lm_head"])
deploy_ptq = RTN(config=deploy_cfg)
w8a16_network = deploy_ptq.apply(w8a16_network)
w8a16_network = deploy_ptq.convert(w8a16_network)
ms.load_checkpoint("./output/w8a16_ckpt/rank_0/w8a16.ckpt", w8a16_network)
[11]:
{'model.tok_embeddings.embedding_weight': Parameter (name=model.tok_embeddings.embedding_weight, shape=(32000, 4096), dtype=Float16, requires_grad=True),
......
'model.layers.31.feed_forward.w3._weight_quantizer.scale': Parameter (name=model.layers.31.feed_forward.w3._weight_quantizer.scale, shape=(11008,), dtype=Float16, requires_grad=True),
'model.layers.31.feed_forward.w3._weight_quantizer.zp_neg': Parameter (name=model.layers.31.feed_forward.w3._weight_quantizer.zp_neg, shape=(11008,), dtype=Float16, requires_grad=True),
'model.norm_out.weight': Parameter (name=model.norm_out.weight, shape=(4096,), dtype=Float32, requires_grad=True),
'lm_head.weight': Parameter (name=lm_head.weight, shape=(32000, 4096), dtype=Float16, requires_grad=True)}
3.4. 评估量化后的网络
本示例对Llama2在wikitext2数据集上评估Perplexity指标。使用步骤1中下载好的分词器和数据集文件分别实例化分词器对象和数据集对象,并实例化PerplexityMetric对象作为metric。
[12]:
net_helper = MFLlama2Helper(network_config)
bs = net_helper.get_spec("batch_size")
seq_len = net_helper.get_spec("seq_length")
tokenizer = net_helper.create_tokenizer()
ds = create_wikitext_dataset("./workspace/wikitext-2/wiki.valid.tokens", bs, seq_len, max_new_tokens=1, tokenizer=tokenizer)
metric = PerplexityMetric()
metric.clear()
data_count = 0
total_count = ds.get_dataset_size()
for _, ds_item in enumerate(ds.create_dict_iterator()):
data_count += 1
logger.info(f"Dataset count: {data_count}/{total_count}")
input_ids = ds_item['input_ids'].asnumpy()
net_inputs = net_helper.assemble_inputs(input_ids)
outputs = w8a16_network(*net_inputs)
metric.update(*outputs)
print('...........Evaluate Over!...............', flush=True)
print(f"W8A16 PPL: {metric.eval()}", flush=True)
[INFO] GE(1746443,python):2024-03-19-19:25:18.990.947 [ge_api.cc:523][status:INIT]1746443 AddGraph:Start to add graph in Session. graph_id: 1, graph_name: kernel_graph224, session_id: 0.
[INFO] GE(1746443,python):2024-03-19-19:25:18.991.481 [ge_api.cc:1154][status:INIT]1746443 CompileGraph:Start to compile graph, graph_id: 1
[INFO] GE(1746443,python):2024-03-19-19:25:18.991.586 [graph_manager.cc:1264][EVENT]1746443 PreRun:PreRun start: graph node size 1, session id 0, graph id 1, graph name kernel_graph224.
[INFO] GE(1746443,python):2024-03-19-19:25:19.065.657 [ge_api.cc:1160][status:STOP]1746443 CompileGraph:Compile graph success.
[INFO] GE(1746443,python):2024-03-19-19:25:19.067.797 [ge_api.cc:787][status:INIT]2453595 RunGraphWithStreamAsync:Session run graph with stream async, session_id: 0, graph_id: 1, input size 0, output size 0
[INFO] GE(1746443,python):2024-03-19-19:25:19.079.152 [ge_api.cc:799][status:STOP]2453595 RunGraphWithStreamAsync:Session run graph with stream async finished.
[INFO] GE(1746443,python):2024-03-19-19:26:40.520.923 [ge_api.cc:523][status:INIT]1746443 AddGraph:Start to add graph in Session. graph_id: 2, graph_name: kernel_graph225, session_id: 0.
[INFO] GE(1746443,python):2024-03-19-19:26:40.581.045 [ge_api.cc:1154][status:INIT]1746443 CompileGraph:Start to compile graph, graph_id: 2
[INFO] GE(1746443,python):2024-03-19-19:26:40.633.523 [graph_manager.cc:1264][EVENT]1746443 PreRun:PreRun start: graph node size 3025, session id 0, graph id 2, graph name kernel_graph225.
[INFO] GE(1746443,python):2024-03-19-19:28:24.659.856 [ge_api.cc:799][status:STOP]2453595 RunGraphWithStreamAsync:Session run graph with stream async finished.
[INFO] GE(1746443,python):2024-03-19-19:28:24.665.855 [ge_api.cc:787][status:INIT]2453595 RunGraphWithStreamAsync:Session run graph with stream async, session_id: 0, graph_id: 2, input size 739, output size 3
[INFO] GE(1746443,python):2024-03-19-19:28:24.667.497 [ge_api.cc:799][status:STOP]2453595 RunGraphWithStreamAsync:Session run graph with stream async finished.
[INFO] GE(1746443,python):2024-03-19-19:28:25.267.844 [ge_api.cc:787][status:INIT]2453595 RunGraphWithStreamAsync:Session run graph with stream async, session_id: 0, graph_id: 3, input size 3, output size 1
......
[INFO] GE(1746443,python):2024-03-19-19:29:18.708.299 [ge_api.cc:799][status:STOP]2453595 RunGraphWithStreamAsync:Session run graph with stream async finished.
W8A16 PPL: {'PerplexityMetric': {'loss': 2.237087654840339, 'PPL': 9.365711954412435}}
步骤4. 效果分析
表3:Llama2 7B网络RTN算法量化前后对比
指标 |
FP16 |
W8A16 |
收益 |
|---|---|---|---|
ckpt-size(GB)↓ |
13 |
7.1 |
-5.9 |
wikitext2-Perplexity↓ |
9.46 |
9.37 |
-0.09 |
可以看到,经过RTN量化算法处理后:
量化后网络的参数量缩减了5.9GB,只剩下原Float16时的54.6%,即网络部署时,用于静态权重存储的显存下降到Float16时的54.6%。因而量化后的网络可以在资源更紧张的环境上部署,或者在相同的环境中提供更大的吞吐量。
量化后网络在wikitext2数据集上的困惑度下降0.09,即量化后网络在wikitext2上生成式任务效果更好。