Quantization Algorithm Overview
![]()
The following describes some basic concepts of quantization algorithms to help users understand the quantization algorithms. If you have a deep understanding of the quantization algorithm, skip to Examples.
Background
With the development of deep learning, neural networks are widely used in various fields. Network performance is improved, but numerous parameters and a large volume of computation are introduced. Deep learning technologies are used on an increasing number of applications running on mobile or edge devices.
Take mobile phones as an example. To provide user-friendly and intelligent services, the AI function is integrated into operating systems and applications which introduce network files and weight files to mobile applications. For example, the original weight files of AlexNet have exceeded 200 MB, and the new networks are developing towards a more complex structure with more parameters.
Due to limited hardware resources of a mobile or edge device, network need to be simplified and the quantization technology is used to solve this problem. Network quantization is a technology that converts floating-point computing into low-bit fixed-point computing. It can effectively reduce the network operational intensity, parameters, and memory consumption, but often causes some accuracy loss.
Quantization Method
Quantization is a process of approximating floating-point weights and inputs to a limited number (usually int8) of discrete values at a low inference accuracy loss. It uses a data type with fewer bits to approximately represent 32-bit floating-point data with a limited range. The input and output of the network are still floating-point data. In this way, the size of network and memory consumption are reduced, and the network inference speed is accelerated.
First, quantization will cause accuracy loss, which is equivalent to introducing noise to a network. However, a neural network is generally insensitive to noise. As long as a quantization degree is well controlled, impact on precision of an advanced task may be very small.
Second, traditional convolution operations use FP32, which takes a lot of time to complete. However, if the weight parameters and activation are quantized to INT8 before being input to each layer, the number of bits and multiplication operations are reduced. In addition, all convolution operations are multiplication and addition operations with integers, which are much faster than floating-point operations.
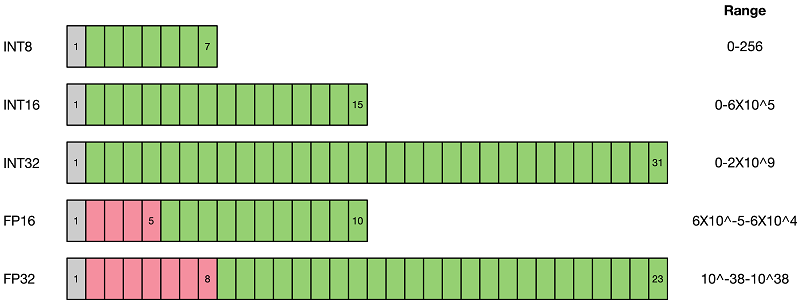
As shown in the preceding figure, compared with the FP32 type, low-precision data representation types such as FP16 and INT8 occupy less space. Replacing the high-precision data representation type with the low-precision data representation type can greatly reduce the storage space and transmission time. Low-bit computing has higher performance. Compared with FP32, INT8 has a three-fold or even higher acceleration ratio. For the same computing, INT8 has obvious advantages in power consumption.
Currently, there are two types of quantization solutions in the industry: quantization aware training and post-training quantization.
(1) Quantization aware training requires training data and has better network accuracy. It is applicable to scenarios that have high requirements on the network compression rate and accuracy. The purpose is to reduce accuracy loss. The forward inference process in which the gradient is involved in network training enables the network to obtain a difference of quantization loss. The gradient update needs to be performed in a floating point. Therefore, the gradient is not involved in a backward propagation process.
(2) Post-training quantization is easy to use. Only a small amount of calibration data is required. It is applicable to scenarios that require high usability and lack of training resources.
Examples
SimQAT algorithm: A basic quantization aware algorithm based on the fake quantization technology
SLB quantization algorithm: A non-linear low-bit quantization aware algorithm