模型分析与准备
![]()
复现算法实现
获取在PyTorch上已实现的参考代码。
分析算法及网络结构,以及算法的创新点(包括数据增强方法、学习率衰减策略、优化器参数、参数初始化方法等)。
复现参考论文实现的精度,获取参考性能数据,并提前识别问题。
请参考复现算法实现详解。
分析API满足度
在实践迁移之前,建议先分析MindSpore对迁移代码中的API支持程度,避免API不支持影响代码实现。
这里分析的API专指网络执行图中的API,包含MindSpore的算子及高级封装API,不包括数据处理中使用的API。数据处理过程中使用的API建议使用三方的实现代替,如numpy,opencv,pandas,PIL等。
分析API满足度有以下两种方式:
使用API自动扫描工具MindSpore Dev Toolkit(推荐)。
手动查询API映射表进行分析。
工具扫描API
MindSpore Dev Toolkit是一款由MindSpore开发的多平台(目前支持在PyCharm和Visual Studio Code上运行)Python IDE插件,可基于文件级别或项目级别进行API扫描。
PyCharm中Dev Toolkit插件使用指南请参考PyCharm API扫描。
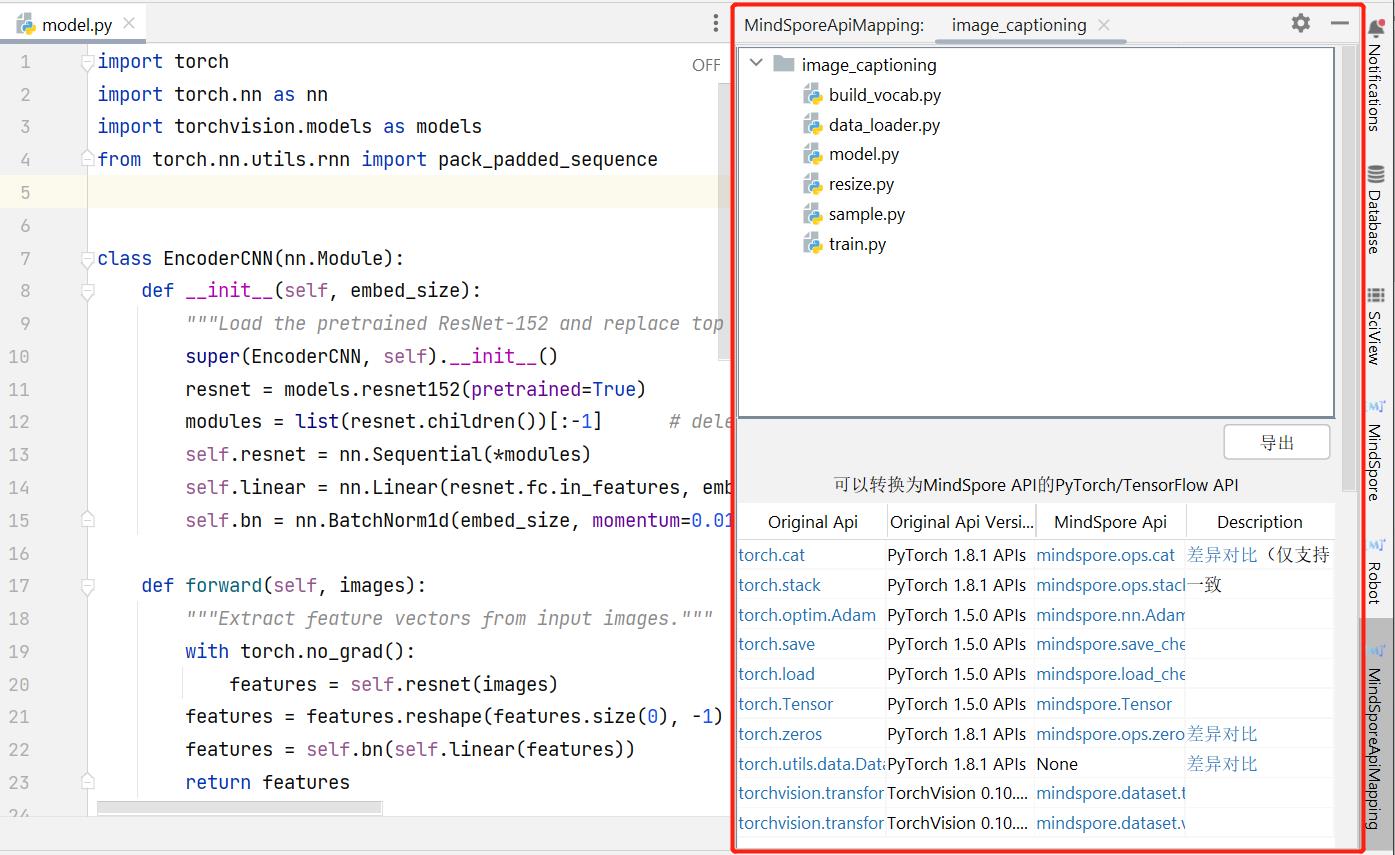
Visual Studio Code中Dev Toolkit插件使用指南请参考Visual Studio Code API扫描。
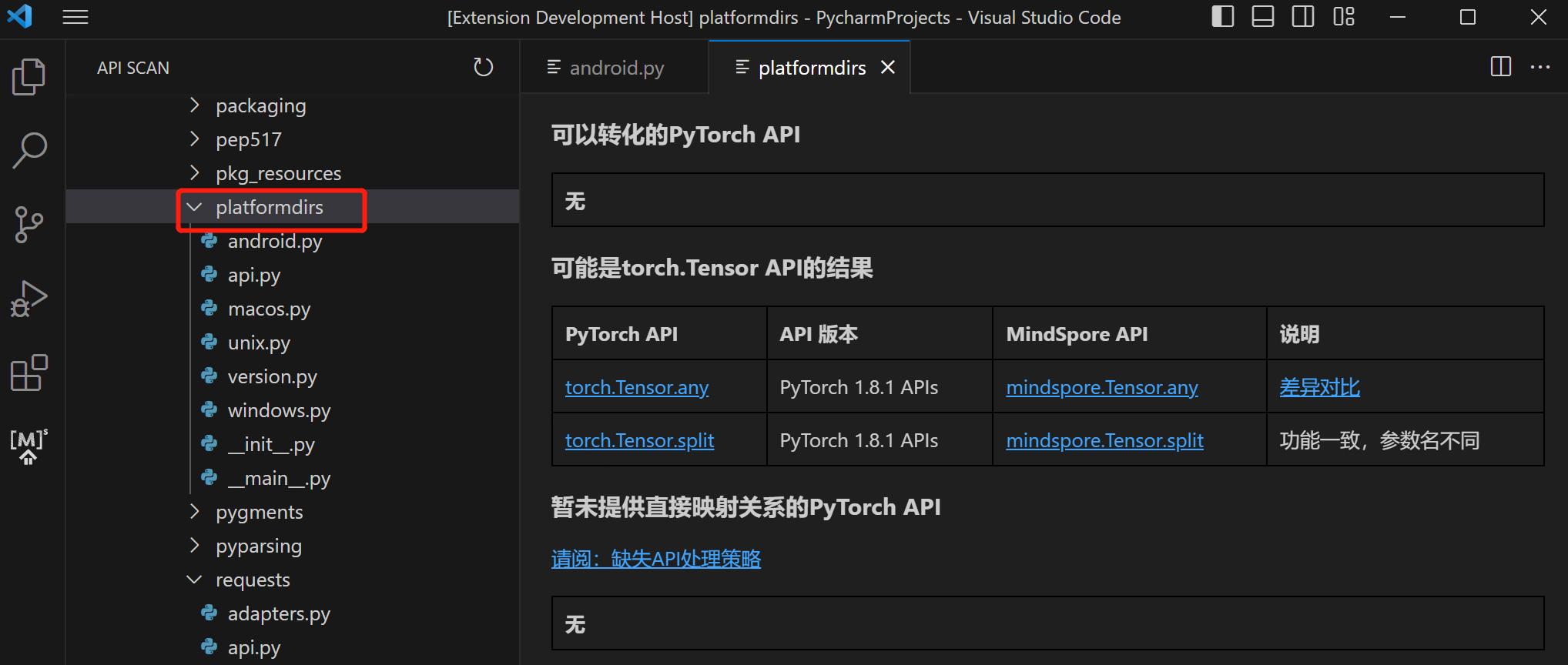
手动查询API映射表
以PyTorch的代码迁移为例,拿到参考代码实现后,可以通过过滤torch,nn,ops等关键字获取使用的API接口,如调用了其他库的方法,需要手动分析。然后对照PyTorch与MindSpore API 映射
或者API 查找对应的API实现。
其他框架API的映射可以参考API命名与功能描述。注意,针对相同功能的API,MindSpore的命名可能与其他框架不同,同名API参数与功能也可能与其他框架有区别,均以官方描述为准。
处理缺失API
如果没有找到对应的API接口,可采用以下策略来处理:
等价替换。
使用已有API包装等价功能逻辑。
自定义算子。
社区求助。
详细处理方法请参考缺失API处理策略。
分析功能满足度
MindSpore仍在持续迭代中,部分功能目前存在限制,在网络迁移过程中可能遇到受限功能使用的情况,所以在迁移之前,需要分析功能满足度。 可从以下几个点进行分析:
动态shape。
稀疏。
动态shape
当前MindSpore的动态shape特性在迭代开发中,动态shape功能支持不完善。
迁移过程中如遇到动态shape相关问题可参考动态shape相关迁移策略。
稀疏
MindSpore现在已经支持最常用的CSR和COO两种稀疏数据格式,但是由于目前支持稀疏算子有限,大部分稀疏的特性还存在限制。 在此情况下,建议优先查找对应的算子是否支持稀疏计算,如不支持的话需要转换成普通算子。具体可查看稀疏。
迁移场景好用功能和特性推荐
MindSpore网络迁移过程中,主要的问题为:精度问题和性能问题。下面将介绍MindSpore定位这两个问题提供的相对成熟的功能及特性。
精度问题
这里主要介绍几个定位精度问题使用到的工具:
可视化数据集。
TroubleShooter。
Dump。
可视化数据集
MindRecord是MindSpore开发的一种高效数据格式,当出现精度问题时,可先检查自己的数据是否处理正确。 如果源数据为TFRecord,可通过TFRecord转换成MindRecord工具,将源数据转为MindRecord直接送入网络进行精度对比。 也可通过可视化TFRecord或MindRecord数据集工具,可视化数据进行数据检查。
TroubleShooter
TroubleShooter是MindSpore网络开发调试工具包,用于提供便捷、易用的调试能力。 当前TroubleShooter支持的功能有:比较两组Tensor值(npy文件)是否相等;比较PyTorch和MindSpore的网络输出是否相等;比对MindSpore与PyTorch的ckpt/pth等。 具体可参考TroubleShooter的应用场景。
Dump
MindSpore提供了Dump功能,用来将模型训练中的图以及算子的输入输出数据保存到磁盘文件,一般用于网络迁移复杂问题定位(例如:算子溢出等)可以dump出算子级别的数据。
获取Dump数据参考:同步Dump数据获取介绍和异步Dump数据获取介绍
分析Dump数据参考:同步Dump数据分析介绍和异步Dump数据分析介绍
具体可参考Dump。
性能问题
性能问题常用定位方法可参考:性能调优指南。 这里主要介绍几个定位性能问题可用的工具:
Profiler。
MindSpore Insight。
Profiler
Profiler可将训练和推理过程中的算子耗时等信息记录到文件中,主要提供框架的host执行、以及算子执行的Profiler分析功能,帮助用户更高效地调试神经网络性能。 当前MindSpore提供两种方式来使能Profiler:修改脚本来获取性能数据和环境变量使能获取性能数据。
MindSpore Insight
MindSpore Insight是一款可视化调试调优工具,帮助用户获得更优的模型精度和性能。通过Profiler获取性能数据之后,可使用MindSpore Insight可视化数据,进而查看训练过程、优化模型性能、调试精度问题。 MindSpore Insight启动等使用介绍可查看MindSpore Insight相关命令。 可视化数据之后,可通过解析性能数据进行数据分析。 更多介绍可查看MindSpore Insight文档。
动态图与静态图
目前主流的深度学习框架有静态图(Graph)和动态图(PyNative)两种执行模式。
静态图模式下,程序在编译执行时,首先生成神经网络的图结构,然后再执行图中涉及的计算操作。因此,在静态图模式下,编译器可以通过使用图优化等技术来获得更好的执行性能,有助于规模部署和跨平台运行。
动态图模式下,程序按照代码的编写顺序逐行执行,在执行正向过程中根据反向传播的原理,动态生成反向执行图。这种模式下,编译器将神经网络中的各个算子逐一下发到设备进行计算操作,方便用户编写和调试神经网络模型。
调用自定义类
在静态图模式下,通过使用jit_class修饰自定义类,用户可以创建、调用该自定义类的实例,并且可以获取其属性和方法。
jit_class应用于静态图模式,扩充完善静态图编译语法的支持范围。在动态图模式即PyNative模式下,jit_class的使用不影响PyNative模式的执行逻辑。
自动微分
自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
混合精度
通常我们训练神经网络模型的时候,默认使用的数据类型为单精度FP32。近年来,为了加快训练时间、减少网络训练时候所占用的内存,并且保存训练出来的模型精度持平的条件下,业界提出越来越多的混合精度训练的方法。这里的混合精度训练是指在训练的过程中,同时使用单精度(FP32)和半精度(FP16)。
自动数据增强
MindSpore除了可以让用户自定义数据增强的使用,还提供了一种自动数据增强方式,可以基于特定策略自动对图像进行数据增强处理。
梯度累加
梯度累加是一种训练神经网络的数据样本按Batch拆分为几个小Batch的方式,然后按顺序计算。目的是为了解决由于内存不足,导致Batch size过大神经网络无法训练或者网络模型过大无法加载的OOM(Out Of Memory)问题。
Summary
训练过程中的标量、图像、计算图、训练优化过程以及模型超参等信息记录到文件中,通过可视化界面供用户查看。
Golden Stick
MindSpore Golden Stick是华为诺亚团队和华为MindSpore团队联合设计开发的一个模型压缩算法集。包含基本的量化和剪枝方法。