Constructing MindSpore Network
This chapter will introduce the related contents of MindSpore scripting, including datasets, network models and loss functions, optimizers, training processes, inference processes from the basic modules needed for training and inference. It will include some functional techniques commonly used in network migration, such as network writing specifications, training and inference process templates, and dynamic shape mitigation strategies.
Network Training Principle
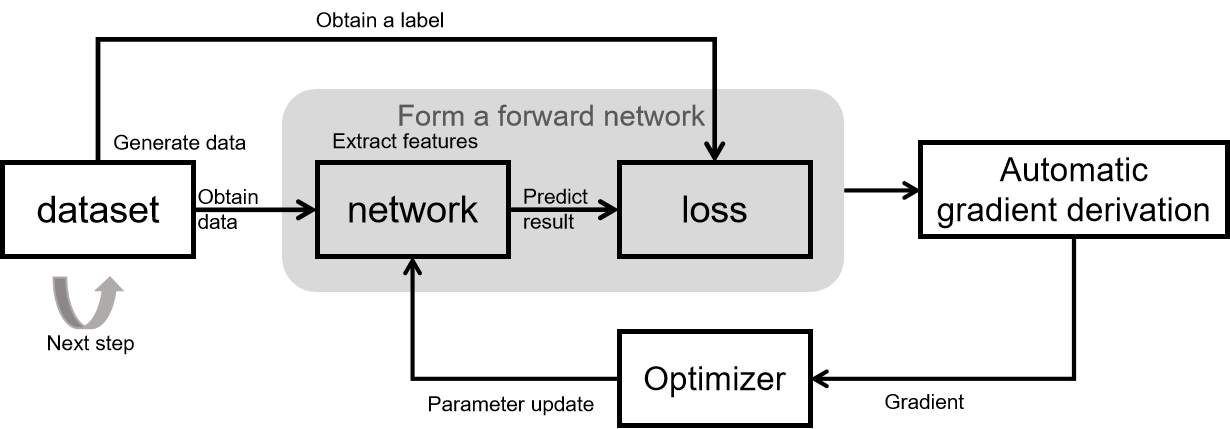
The basic principle of network training is shown in the figure above.
The training process of the whole network consists of 5 modules:
dataset: for obtaining data, containing input of network and labels. MindSpore provides a basic common dataset processing interface, and also supports constructing datasets by using python iterators.
network: network model implementation, typically encapsulated by using Cell. Declare the required modules and operators in init, and implement graph construction in construct.
loss: loss function. Used to measure the degree of difference between the predicted value and the true value. In deep learning, model training is the process of shrinking the loss function value by iterating continuously. Defining a good loss function can help the loss function value converge faster to achieve better precision. MindSpore provides many common loss functions, but of course you can define and implement your own loss function.
Automatic gradient derivation: Generally, network and loss are encapsulated together as a forward network and the forward network is given to the automatic gradient derivation module for gradient calculation. MindSpore provides an automatic gradient derivation interface, which shields the user from a large number of derivation details and procedures and greatly reduces the threshold of framework. When you need to customize the gradient, MindSpore also provides interface to freely implement the gradient calculation.
Optimizer: used to calculate and update network parameters during model training. MindSpore provides a number of general-purpose optimizers for users to choose, and also supports users to customize the optimizers.
Principles of Network Inference
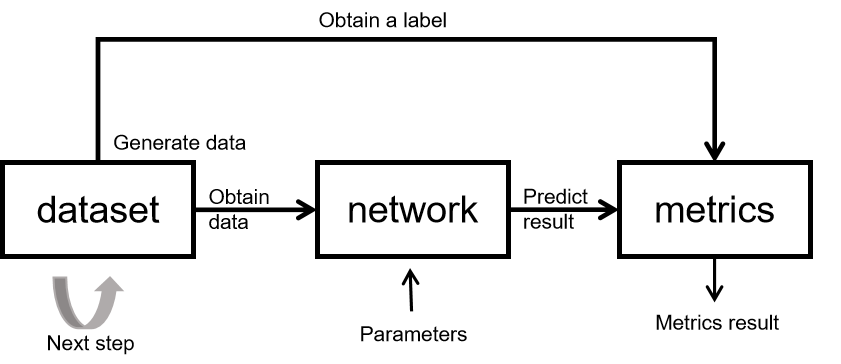
The basic principles of network inference are shown in the figure above.
The training process of the whole network consists of 3 modules:
dataset: used to obtain data, including the input of the network and labels. Since entire inference dataset needs to be inferred during inference process, batchsize is recommended to set to 1. If batchsize is not 1, note that when adding batch, add drop_remainder=False. In addition the inference process is a fixed process. Loading the same parameters every time has the same inference results, and the inference process should not have random data augmentation.
network: network model implementation, generally encapsulated by using Cell. The network structure during inference is generally the same as the network structure during training. It should be noted that Cell is tagged with set_train(False) for inference and set_train(True) for training, just like PyTorch model.eval() (model evaluation mode) and model.train() (model training mode).
metrics: When the training task is over, evaluation metrics (Metrics) and evaluation functions are used to assess whether the model works well. Commonly used evaluation metrics include Confusion Matrix, Accuracy, Precision, and Recall. The mindspore.nn module provides the common evaluation functions, and users can also define their own evaluation metrics as needed. Customized Metrics functions need to inherit train.Metric parent class and reimplement the clear method, update method and eval method of the parent class.
Constructing Network
Note
When doing network migration, we recommend doing inference validation of the model as a priority after completing the network scripting. This has several benefits:
Compared with training, the inference process is fixed and able to be compared with the reference implementation.
Compared with training, the time required for inference is relatively short, enabling rapid verification of the correctness of the network structure and inference process.
The trained results need to be validated through the inference process to verify results of the model. It is necessary that the correctness of the inference be ensured first, then to prove that the training is valid.